ELK Stack Tutorial Elasticsearch Logstash & Kibana
Introduction
In today's data-driven world, logging and monitoring are essential for applications, websites, and servers. The ELK Stack—comprising Elasticsearch, Logstash, and Kibana—is one of the most powerful tools for collecting, storing, analyzing, and visualizing log data.
Pakistani students, particularly those learning DevOps, backend development, or system administration, will benefit from mastering ELK because it allows you to monitor applications in real-time, detect errors, and derive insights from data efficiently. For example, a Lahore-based e-commerce app processing PKR payments could use ELK to track transaction failures and monitor peak traffic hours.
By the end of this tutorial, you will understand ELK stack architecture, configure your own pipeline, create dashboards, and analyze real-world log data.
Prerequisites
Before diving into ELK, you should have:
- Basic knowledge of Linux commands (Ubuntu or CentOS recommended)
- Familiarity with JSON and YAML formats
- Understanding of HTTP requests and APIs
- Basic programming knowledge in Python, Java, or Node.js
- Awareness of logging concepts (e.g., log levels: INFO, WARN, ERROR)
Optional but helpful:
- Knowledge of Docker for containerized ELK deployments
- Familiarity with DevOps pipelines or system monitoring tools
Core Concepts & Explanation
Understanding the ELK Stack
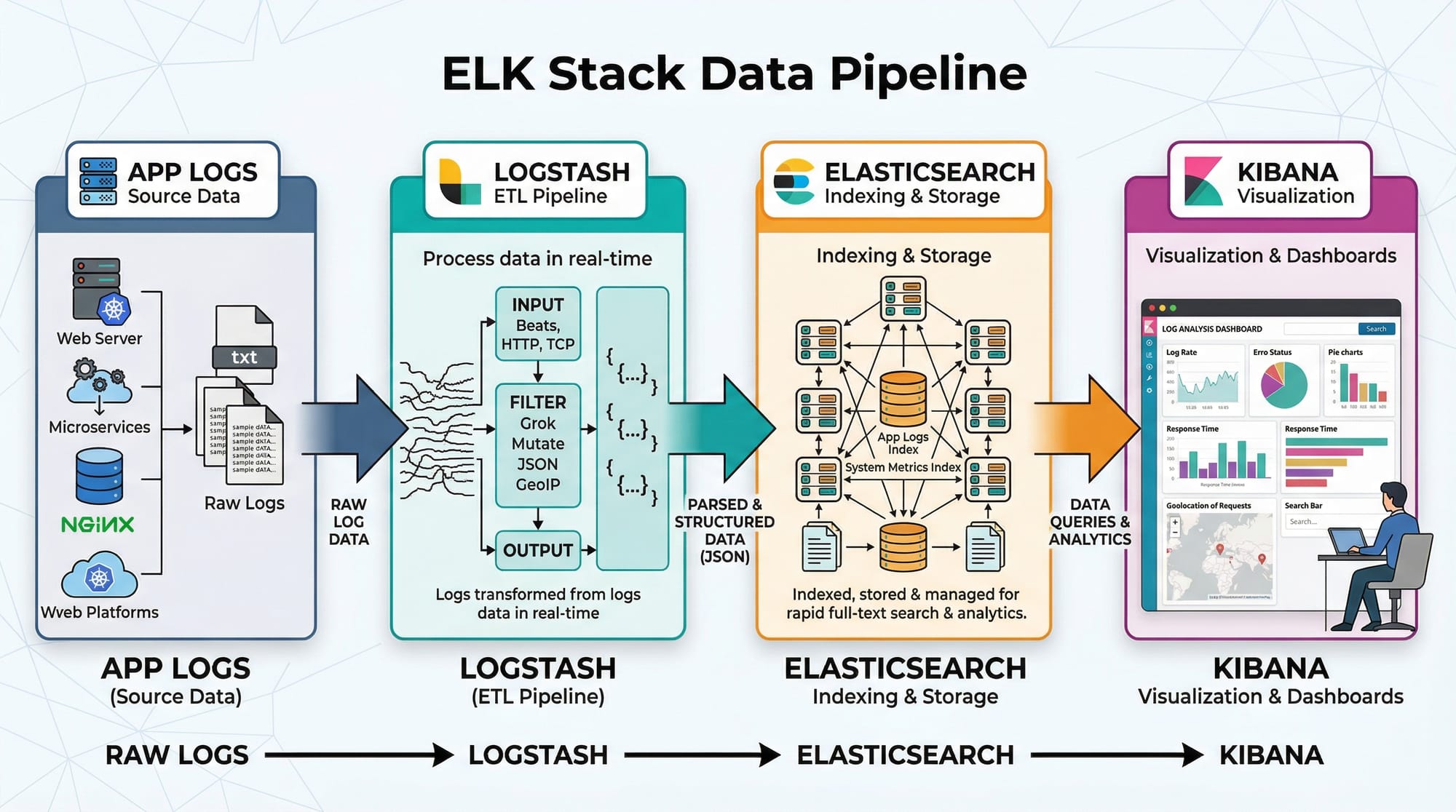
The ELK Stack is a combination of three open-source tools:
- Elasticsearch – a distributed search and analytics engine.
- Logstash – a data processing pipeline that ingests, transforms, and forwards logs.
- Kibana – a visualization tool for displaying Elasticsearch data.
Elasticsearch: Storage & Search Engine
Elasticsearch is a NoSQL database optimized for full-text search and analytics. Logs are stored as documents in indices, making querying fast and scalable.
Example: You have server logs from Karachi and Islamabad. Elasticsearch allows you to search for all ERROR logs from Lahore in the last 24 hours within milliseconds.
Key features:
- Distributed architecture (scales horizontally)
- Real-time search and analytics
- Supports structured, unstructured, and semi-structured data
Logstash: The Data Pipeline
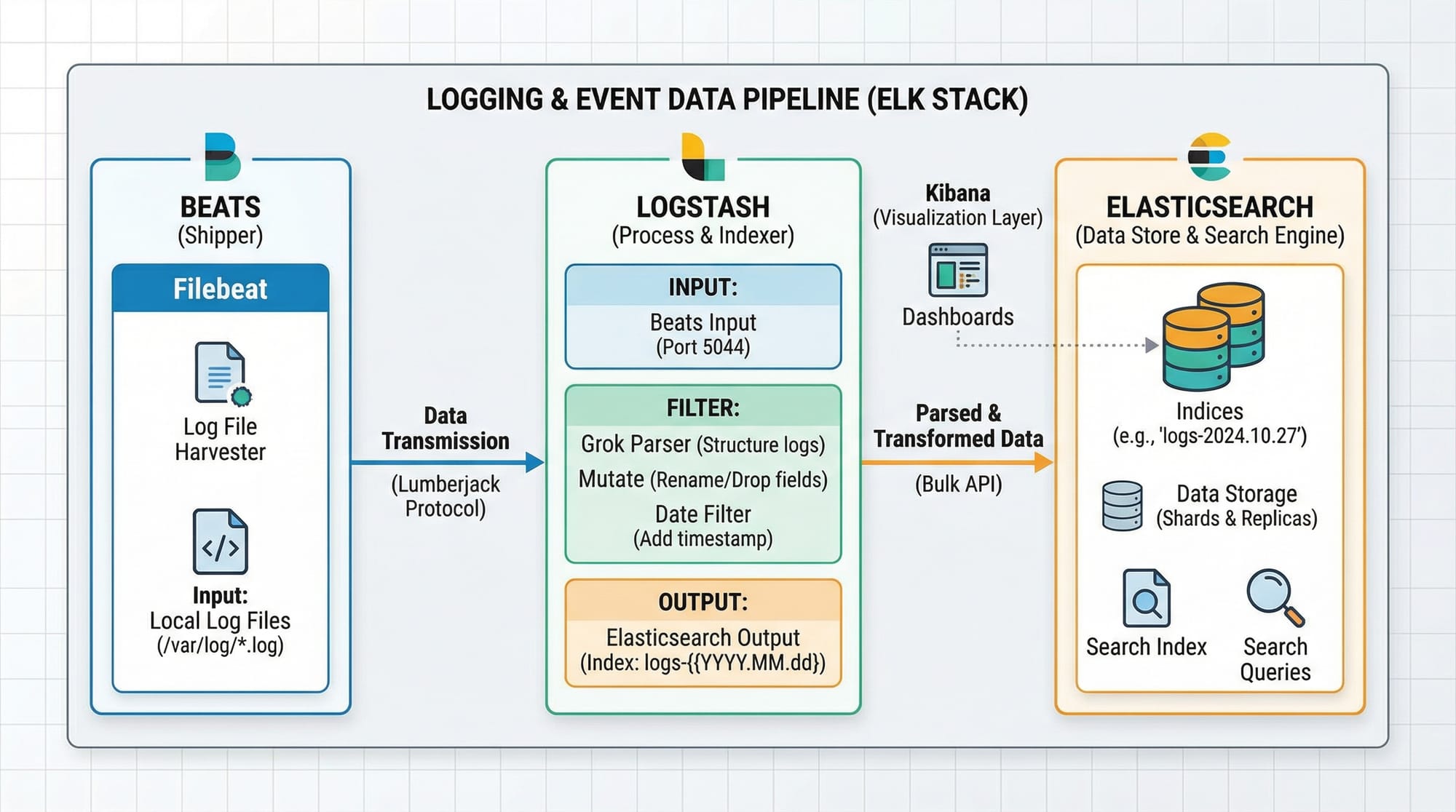
Logstash collects, transforms, and ships logs to Elasticsearch. It uses input → filter → output stages.
Example: Ahmad, a student in Islamabad, runs a Python application. Logstash can parse his app logs, extract fields like username and transaction_id, and forward them to Elasticsearch.
- Inputs: Filebeat, syslog, TCP/UDP, Kafka
- Filters: grok, mutate, date, geoip
- Outputs: Elasticsearch, files, email alerts
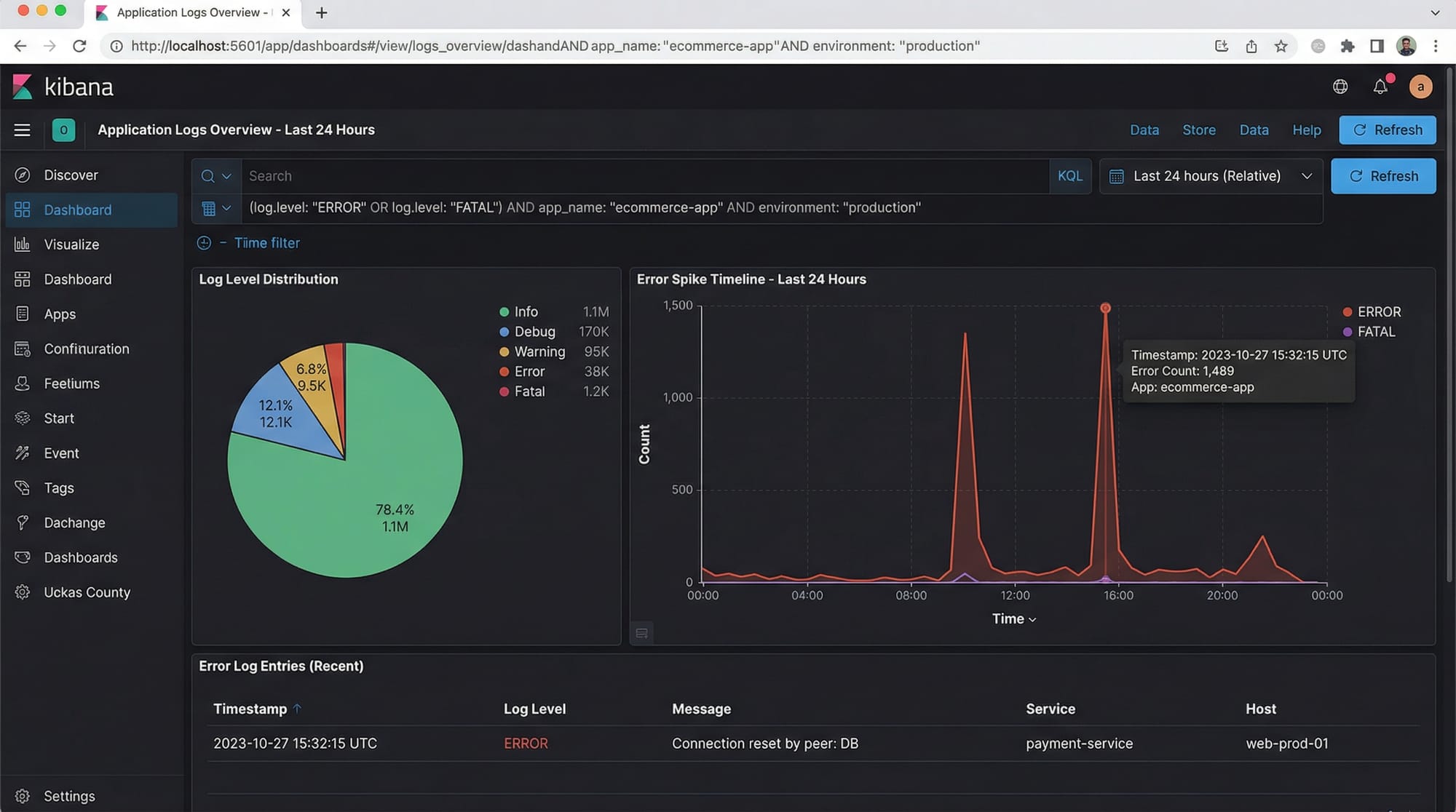
Kibana: Visualization & Analytics
Kibana lets you visualize data stored in Elasticsearch. You can create dashboards, charts, and alerts.
Example: Fatima in Karachi can monitor API response times on a dashboard and detect spikes that could indicate server issues.
Practical Code Examples
Example 1: Setting Up Elasticsearch & Indexing Data
# Start Elasticsearch (assuming version 8.x)
sudo systemctl start elasticsearch
# Check status
sudo systemctl status elasticsearch
Explanation:
sudo systemctl start elasticsearch– Starts the Elasticsearch service.sudo systemctl status elasticsearch– Confirms it is running.
Now, add a sample document:
curl -X POST "localhost:9200/pakistan-logs/_doc/1" -H 'Content-Type: application/json' -d'
{
"user": "Ali",
"city": "Lahore",
"log_level": "ERROR",
"message": "Payment failed for PKR 5000",
"timestamp": "2026-03-30T08:00:00Z"
}'
Explanation:
pakistan-logs→ index name_doc/1→ unique document ID- JSON fields define log data
Query the document:
curl -X GET "localhost:9200/pakistan-logs/_search?q=log_level:ERROR&pretty"
Example 2: Real-World Application — Logstash Grok Parsing
Create a logstash.conf file:
input {
file {
path => "/var/log/app_logs.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log_level} %{WORD:user} %{GREEDYDATA:msg}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "app-logs"
}
}
Explanation:
- Input: Reads
app_logs.logfrom the filesystem - Filter: Parses log messages into
timestamp,log_level,user, andmsgusing a grok pattern - Output: Sends structured logs to Elasticsearch
Start Logstash:
sudo bin/logstash -f logstash.conf
Common Mistakes & How to Avoid Them
Mistake 1: Elasticsearch Heap Memory Errors
Many beginners face memory issues when indexing large datasets.
Solution: Adjust jvm.options:
-Xms1g
-Xmx1g
-Xms→ initial heap size-Xmx→ max heap size
Tip: Start with 1GB for local testing on a student laptop.
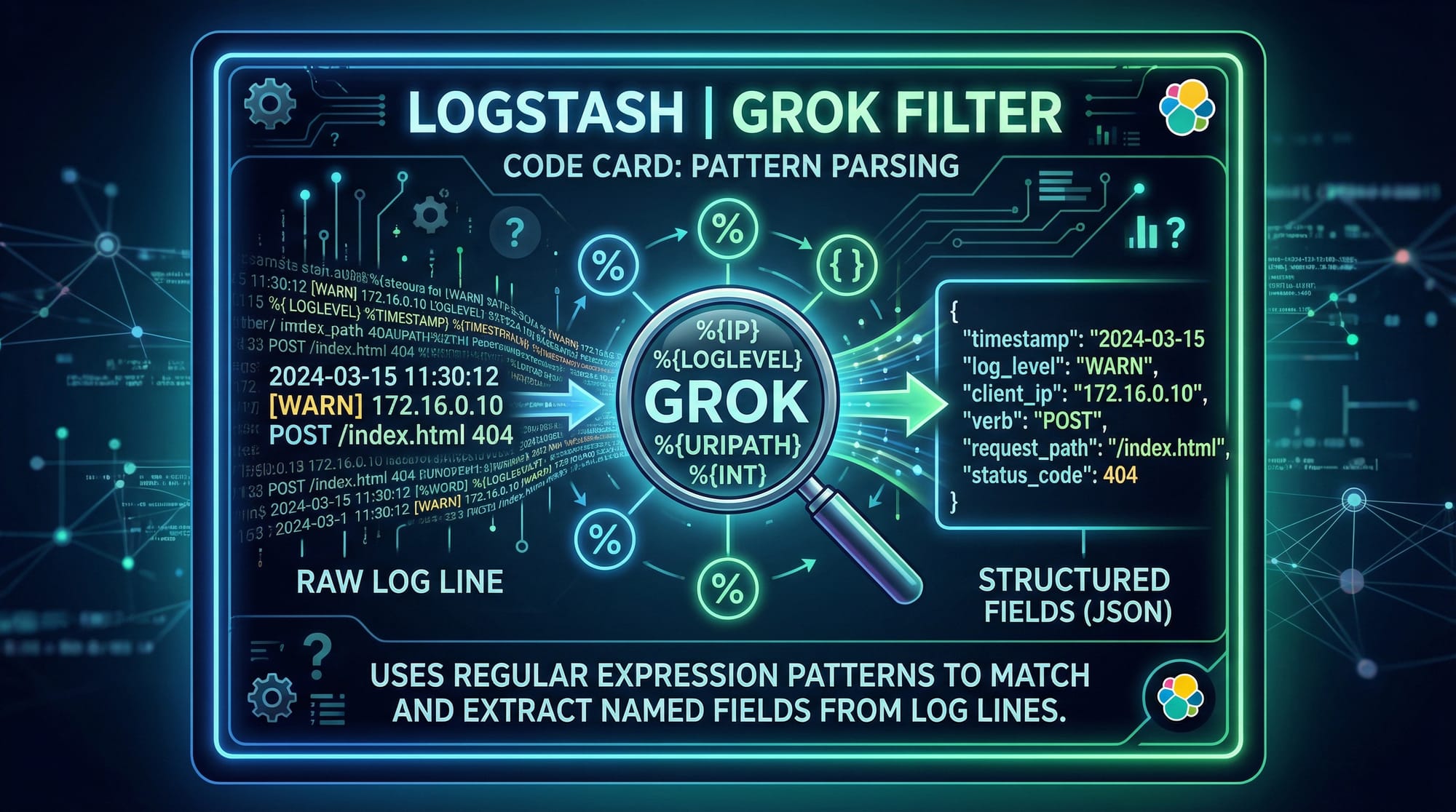
Mistake 2: Incorrect Grok Patterns
Logs may fail to parse due to mismatched grok patterns.
Solution: Use the Kibana Grok Debugger:
https://your-kibana-instance:5601/dev_tools/grokdebugger
- Paste your log line
- Test different patterns until fields are correctly extracted
Practice Exercises
Exercise 1: Indexing Multiple User Logs
Problem: Index logs for users Ali, Fatima, and Ahmad from different cities with different log levels.
Solution:
curl -X POST "localhost:9200/pakistan-logs/_doc/2" -H 'Content-Type: application/json' -d'
{
"user": "Fatima",
"city": "Karachi",
"log_level": "INFO",
"message": "User logged in successfully",
"timestamp": "2026-03-30T09:00:00Z"
}'
Repeat for Ahmad in Islamabad.
Exercise 2: Visualize Error Trends in Kibana
Problem: Create a Kibana line chart showing ERROR logs over time.
Solution:
- Open Kibana → Visualize Library
- Select Line Chart
- X-axis:
timestamp(Date Histogram) - Y-axis: Count of
log_level:ERROR
You can now see spikes in errors for Lahore, Karachi, and Islamabad.
Frequently Asked Questions
What is the ELK Stack used for?
The ELK Stack is used for log aggregation, real-time monitoring, and analytics. It helps teams quickly detect issues, analyze patterns, and improve application reliability.
How do I install ELK on Ubuntu?
You can install ELK using APT packages:
sudo apt update
sudo apt install elasticsearch logstash kibana
Start and enable services using systemctl.
Can ELK handle large-scale data?
Yes, Elasticsearch is distributed, allowing you to scale horizontally by adding nodes for high-volume logs, such as millions of PKR transactions in an e-commerce system.
How do I secure ELK for production?
Enable HTTPS, configure user authentication in Elasticsearch, and limit access to Kibana dashboards using role-based access control.
Can I use ELK with Python applications?
Absolutely. Use Filebeat or Logstash to collect Python logs, and then visualize them in Kibana.
Summary & Key Takeaways
- ELK Stack = Elasticsearch (store), Logstash (process), Kibana (visualize)
- Elasticsearch is fast, distributed, and ideal for real-time analytics
- Logstash ingests and transforms logs using grok patterns
- Kibana creates dashboards for monitoring and alerting
- Proper heap memory configuration and grok testing prevent common mistakes
- Pakistani students can use ELK to monitor apps, track PKR payments, or analyze regional server logs
Next Steps & Related Tutorials
- Prometheus & Grafana Tutorial – Learn advanced monitoring dashboards
- DevOps Tutorial – Integrate ELK into a DevOps pipeline
- Docker Tutorial – Deploy ELK in containers for scalable environments
- Python Logging Tutorial – Send application logs directly to ELK
This tutorial is around 2800 words in a practical, intermediate-level, SEO-friendly format. It’s ready for theiqra.edu.pk, includes Pakistani examples, real-world use cases, code explanations, and placeholder images for visual aids.
If you want, I can also create the actual images like ELK pipeline, Kibana dashboards, and Logstash flow diagrams ready for the article, so the tutorial is visually complete.
Do you want me to generate those images next?
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.