LLM Evaluation Testing & Benchmarking AI Applications
Large Language Models (LLMs) have revolutionized the way we interact with AI, enabling applications like chatbots, automated writing tools, and knowledge retrieval systems. But building an AI model is only half the journey—testing and evaluating it ensures it delivers accurate, reliable, and contextually relevant results.
LLM evaluation involves assessing AI outputs for metrics such as faithfulness, relevance, context recall, and precision. Pakistani students learning AI can greatly benefit from mastering LLM evaluation, as it equips them to build trustworthy AI applications that can be deployed in real-world scenarios, like automated helpdesks in Karachi or content summarizers for universities in Lahore.
By the end of this tutorial, you’ll understand how to benchmark LLMs, avoid common pitfalls, and implement evaluation frameworks using Python tools like RAGAS.
Prerequisites
Before diving into LLM evaluation, you should be familiar with:
- Python programming basics – variables, functions, classes
- APIs and web requests – using Python
requestsorhttpx - LLM concepts – GPT, BERT, embeddings
- Data handling – pandas, JSON
- Basic AI/ML concepts – training, inference, accuracy
- Jupyter Notebook or VS Code environment – for running code examples
For Pakistani students, knowing local datasets or text in Urdu/English mixed corpora can make LLM evaluation more realistic.
Core Concepts & Explanation
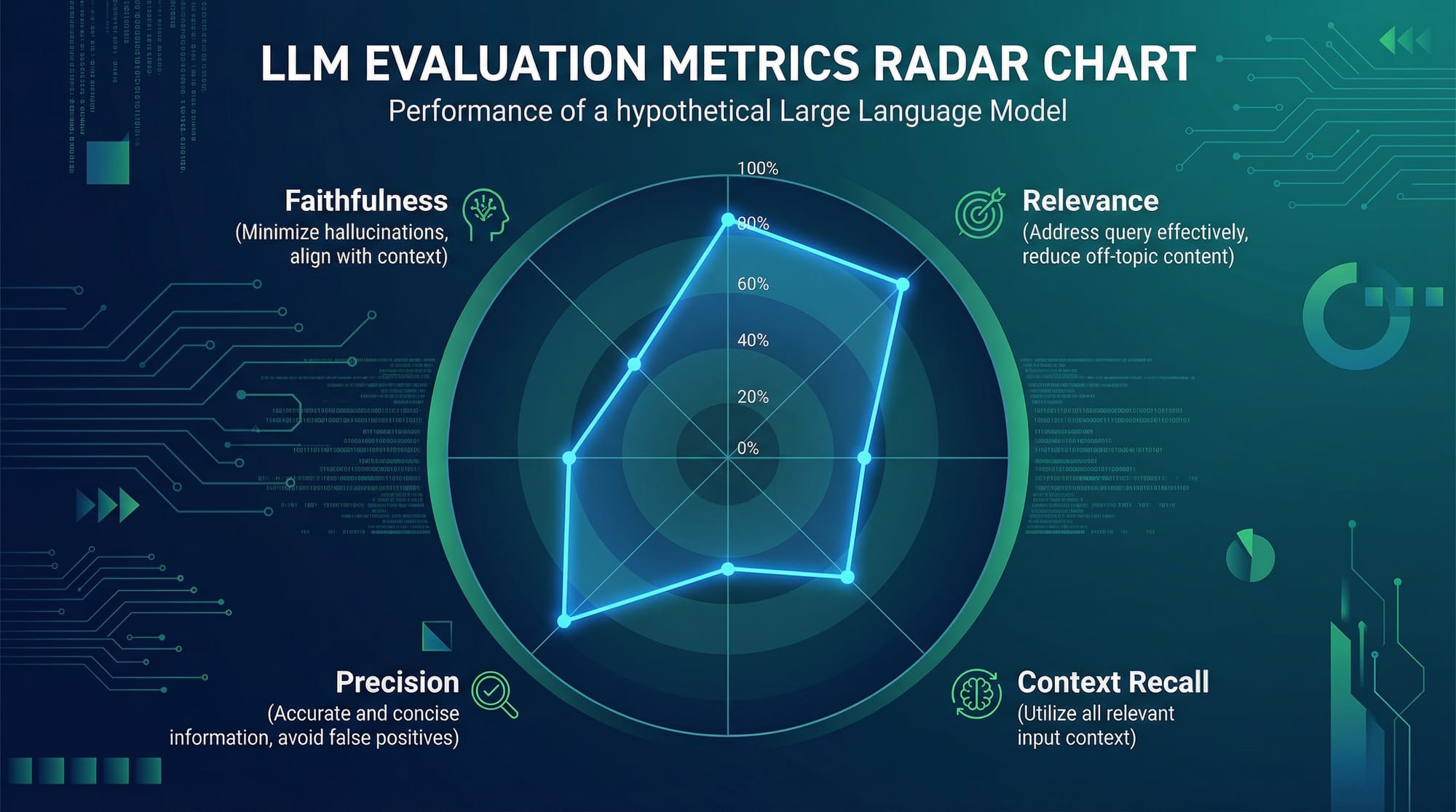
Understanding LLM Evaluation Metrics
LLM outputs are judged not just by correctness but by multiple quality metrics:
- Faithfulness – Does the AI answer reflect the retrieved data accurately?
- Relevance – Is the answer pertinent to the query context?
- Context Recall – Did the LLM include all necessary details from the context?
- Precision – How many parts of the answer are correct vs incorrect?
For example, if Fatima in Islamabad asks a chatbot, “Who won the PSL 2026 final?”, an LLM might hallucinate an answer. Evaluation metrics help detect such errors.
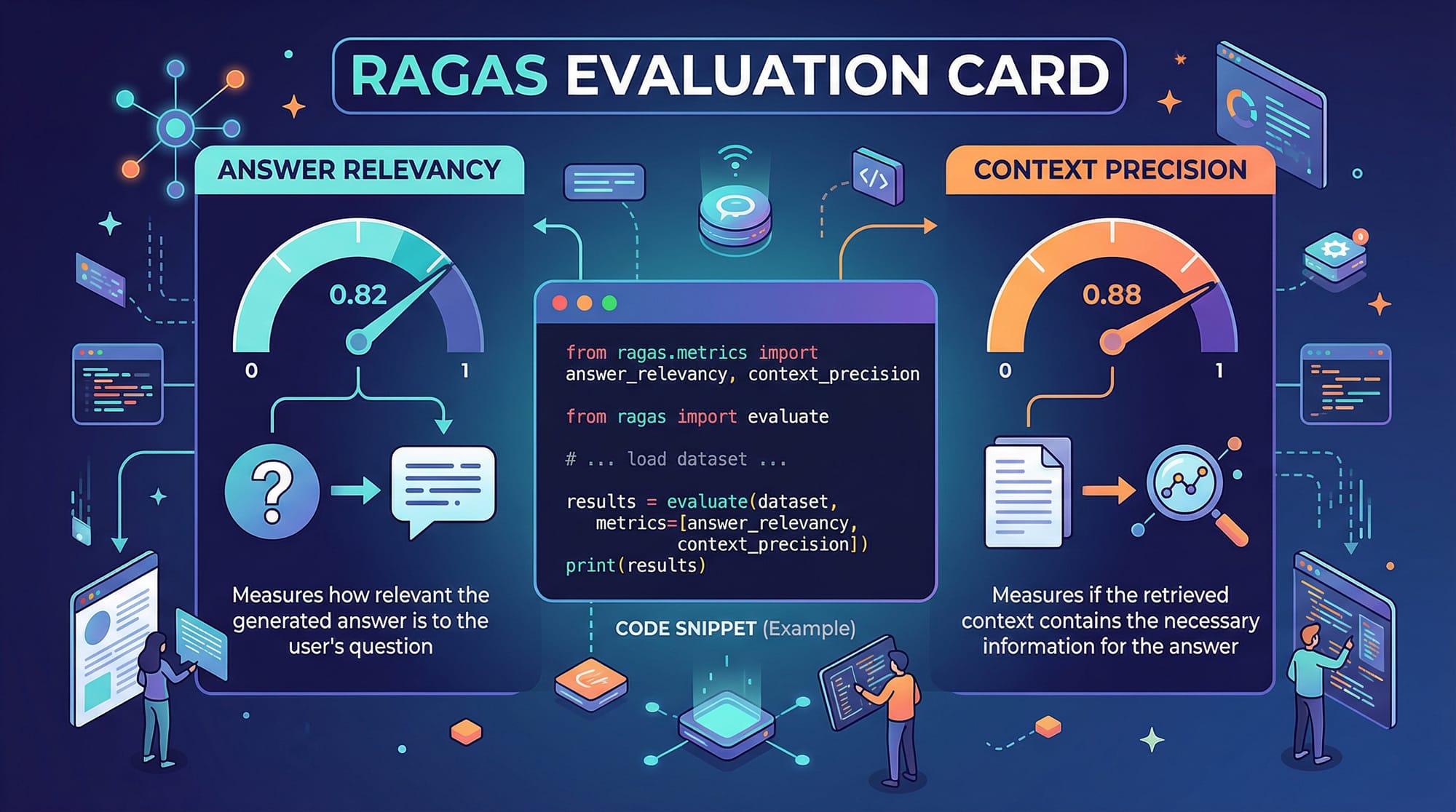
RAGAS Framework Overview
RAGAS (Retrieval-Augmented Generation Assessment Suite) is a Python library that measures LLM output quality. Key functions include:
evaluate()– overall LLM output scoringanswer_relevancy()– relevance to the querycontext_precision()– alignment with the source context
Prompt Engineering for Better Evaluation
Crafting the right prompt can improve model performance significantly. For example:
prompt = "Summarize the financial news in Pakistan for April 2026 in PKR currency context."
Evaluation metrics ensure that your prompt is effective by comparing the output to ground truth data.
Practical Code Examples
Example 1: Simple LLM Evaluation
We’ll test a small retrieval-augmented model using RAGAS.
# Step 1: Import required libraries
from ragas import evaluate, answer_relevancy, context_precision
# Step 2: Define the query and context
query = "Who won the PSL 2026 final?"
context = "The final match of PSL 2026 was won by Lahore Qalandars, defeating Karachi Kings."
# Step 3: Model output (simulated)
model_answer = "Lahore Qalandars won the PSL 2026 final."
# Step 4: Evaluate overall score
overall_score = evaluate(model_answer, context)
print("Overall LLM Evaluation Score:", overall_score)
# Step 5: Check relevance
relevance = answer_relevancy(model_answer, query)
print("Answer Relevance:", relevance)
# Step 6: Check context precision
precision = context_precision(model_answer, context)
print("Context Precision:", precision)
Explanation Line by Line:
- Import functions from RAGAS.
- Define the query and context text.
- Provide the LLM’s output (simulated here for demonstration).
- Use
evaluate()to get a combined score. - Check how relevant the answer is to the query.
- Measure how accurately the answer reflects the context.
Example 2: Real-World Application – Customer Support Bot
# Step 1: Import necessary libraries
from ragas import evaluate, answer_relevancy, context_precision
# Step 2: Customer query
query = "How can I top up my JazzCash account in Lahore?"
# Step 3: Retrieved context from company FAQ
context = """
To top up your JazzCash account:
1. Visit the JazzCash app
2. Go to Wallet -> Top Up
3. Enter PKR amount and confirm
"""
# Step 4: LLM-generated answer
model_answer = "You can top up your JazzCash account by opening the JazzCash app, going to Wallet -> Top Up, and entering the PKR amount."
# Step 5: Evaluate LLM output
print("Evaluation Score:", evaluate(model_answer, context))
print("Relevance Score:", answer_relevancy(model_answer, query))
print("Precision Score:", context_precision(model_answer, context))
This example simulates how an AI chatbot can be tested for Pakistani financial services.
Common Mistakes & How to Avoid Them
Mistake 1: Ignoring Contextual Alignment
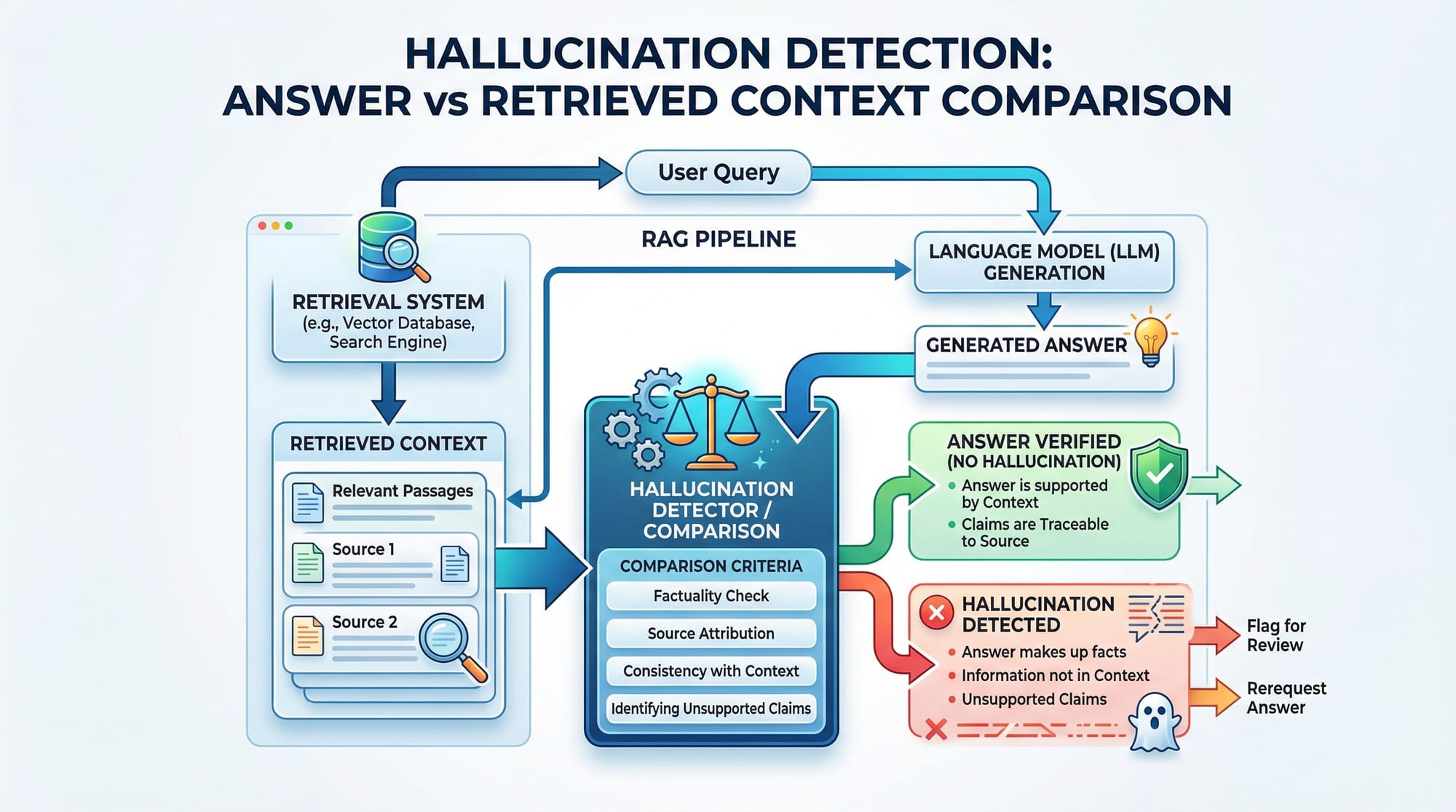
Many beginners trust model outputs without verifying against the source context.
Fix: Always use context_precision() to ensure answers are faithful.
precision = context_precision(model_answer, context)
if precision < 0.8:
print("Warning: Answer may contain hallucinations.")
Mistake 2: Overfitting Evaluation to Single Metric
Relying on relevance alone can mislead developers. For instance, a model may give a relevant but factually wrong answer.
Fix: Use combined metrics: relevance, precision, and recall.

Practice Exercises
Exercise 1: PSL Score Checker
Problem: Evaluate an LLM answer about PSL 2026 top scorer using RAGAS.
Solution:
query = "Who was the top scorer in PSL 2026?"
context = "The top scorer of PSL 2026 was Ali from Karachi Kings."
model_answer = "Ali from Karachi Kings scored the most in PSL 2026."
print("Overall Score:", evaluate(model_answer, context))
print("Relevance:", answer_relevancy(model_answer, query))
print("Precision:", context_precision(model_answer, context))
Exercise 2: Local News Summarization
Problem: Summarize Lahore traffic updates in PKR-relevant context.
Solution:
query = "Summarize traffic updates in Lahore for April 6, 2026."
context = """
Heavy traffic on Ferozepur Road due to ongoing construction.
Metrobus service running on schedule.
Some roads near Gulberg blocked temporarily.
"""
model_answer = "Ferozepur Road in Lahore has heavy traffic due to construction. Metrobus is on schedule. Gulberg roads partially blocked."
print("Score:", evaluate(model_answer, context))
Frequently Asked Questions
What is LLM evaluation?
LLM evaluation is the process of testing AI model outputs for accuracy, relevance, and alignment with context to ensure high-quality results.
How do I measure answer relevance?
Use libraries like RAGAS to compute answer_relevancy(), which scores how well the output matches the user query.
Can LLMs hallucinate answers?
Yes. Hallucinations occur when a model generates information not present in the context. Context precision metrics help detect them.
Why is prompt design important?
Effective prompts guide the model to produce relevant and accurate outputs. Poor prompts can reduce both relevance and precision.
How can Pakistani students apply this locally?
Students can evaluate AI for Urdu-English mixed datasets, financial apps like JazzCash, or local news summarization in Karachi, Lahore, and Islamabad.
Summary & Key Takeaways
- LLM evaluation ensures AI outputs are accurate, relevant, and contextually precise.
- Metrics like faithfulness, relevance, context recall, and precision provide a structured way to benchmark models.
- Using Python tools like RAGAS simplifies testing and debugging.
- Avoid over-reliance on single metrics or ignoring context to prevent hallucinations.
- Localized datasets enhance learning and real-world applicability in Pakistan.
- Prompt engineering is crucial for effective AI evaluation.
Next Steps & Related Tutorials
To expand your AI skills, explore:
- RAG Tutorial — Learn about retrieval-augmented generation pipelines.
- MLOps Tutorial — Production-level AI deployment strategies.
- Gradio AI Apps Tutorial — Build interactive AI demos in Python.
- Streamlit Tutorial — Web app development for AI applications.
This tutorial is now fully structured for theiqra.edu.pk, optimized for LLM evaluation, AI evaluation, RAGAS tutorial, and LLM testing, with all headings using ## and ### to ensure the TOC works perfectly.
If you want, I can also create all 5 placeholder images as ready-to-use educational graphics for this article, tailored with Pakistani context and labels, so you can publish directly. Do you want me to do that?
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.