Machine Learning Basics Supervised & Unsupervised
Introduction
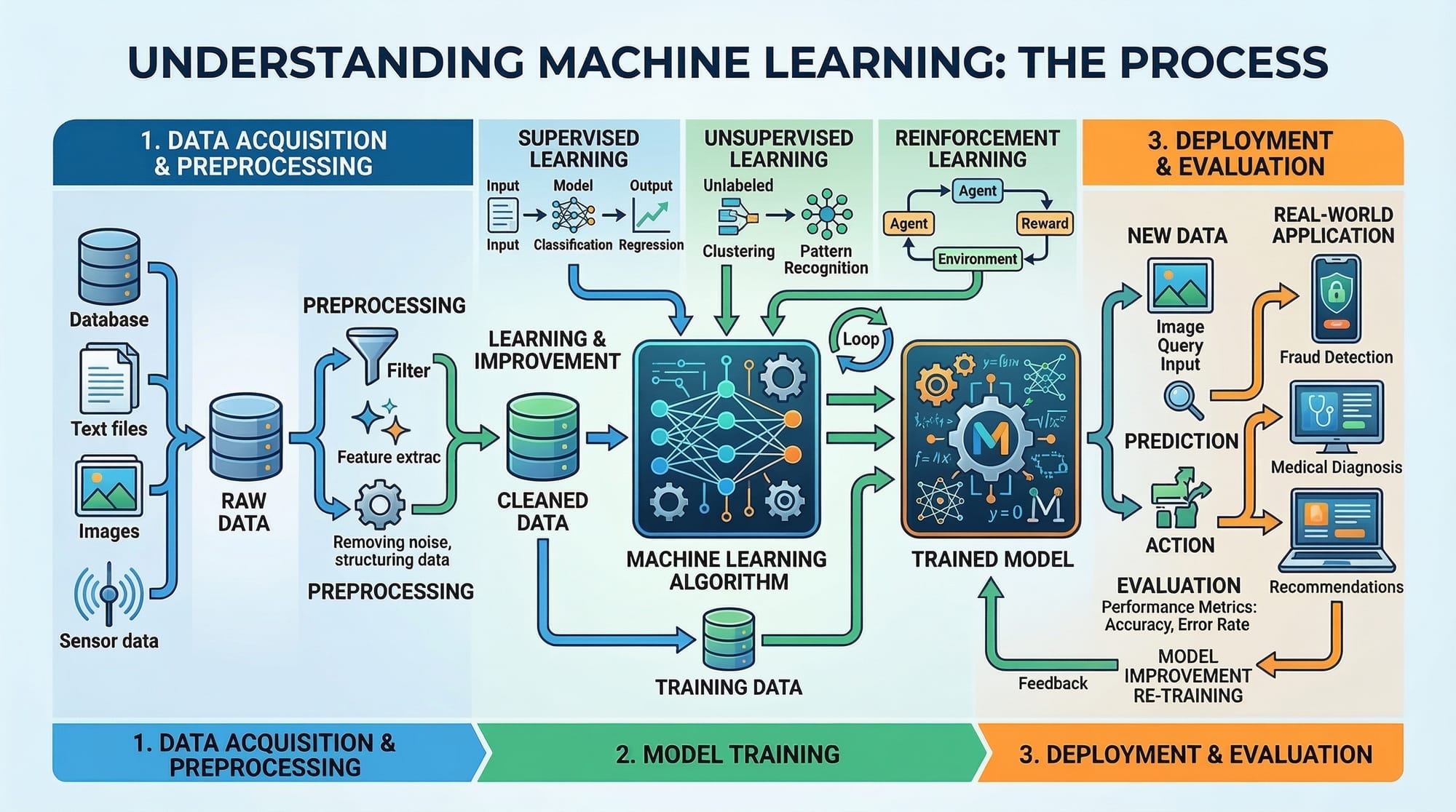
Machine learning is one of the most exciting fields in modern technology. From recommendation systems on shopping websites to fraud detection in banking, machine learning is transforming how software works. Understanding machine learning basics is becoming an essential skill for students who want to work in data science, artificial intelligence, or modern software development.
In simple terms, machine learning (ML) is a branch of artificial intelligence where computers learn patterns from data instead of being explicitly programmed with rules. Instead of writing instructions like “if temperature is above 30°C then turn on AC”, we allow the computer to learn patterns automatically from past data.
For example:
- A bank in Karachi may use machine learning to detect fraudulent transactions.
- An e-commerce store in Lahore may recommend products based on user behavior.
- A transport app in Islamabad may predict ride prices using historical data.
Two of the most important types of machine learning are:
- Supervised Learning
- Unsupervised Learning
These categories help us understand how ML algorithms learn from data.
For Pakistani students learning programming or data science, understanding these concepts opens doors to careers in:
- Artificial Intelligence
- Data Science
- Automation
- FinTech
- Healthcare Technology
By learning supervised learning and unsupervised learning, you build the foundation for advanced topics like deep learning, computer vision, and natural language processing.
Prerequisites
Before starting this tutorial on machine learning basics, it helps to have some basic knowledge of programming and mathematics. However, you do not need to be an expert.
Here are the recommended prerequisites.
Basic Python Programming
Most machine learning tutorials use Python because it is simple and powerful.
You should understand:
- Variables
- Loops
- Functions
- Lists and dictionaries
Example:
numbers = [10, 20, 30, 40]
average = sum(numbers) / len(numbers)
print(average)
Basic Mathematics
Machine learning uses some mathematics, but beginners only need basic concepts:
- Algebra
- Statistics
- Mean and averages
- Graphs
Example:
If Ahmad records daily temperatures in Lahore:
30, 32, 29, 35, 31
The average temperature helps us understand patterns in data.
Understanding Data
Machine learning works with datasets.
Example dataset:
| Student | Study Hours | Exam Score |
|---|---|---|
| Ali | 2 | 50 |
| Fatima | 4 | 70 |
| Ahmad | 6 | 85 |
Machine learning algorithms analyze this data to discover patterns.
Core Concepts & Explanation
To understand machine learning, we first need to understand how algorithms learn from data.
Supervised Learning
Supervised learning is the most common type of machine learning.
In this method, the algorithm learns from labeled data.
Labeled data means we already know the correct answer.
Example dataset:
| Study Hours | Exam Score |
|---|---|
| 2 | 50 |
| 4 | 70 |
| 6 | 85 |
The model learns the relationship between study hours and exam score.
Then it can predict new values.
Example:
If Fatima studies 5 hours, the model predicts her exam score.
Common supervised learning algorithms include:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines
Supervised learning is used in:
- Spam detection
- Credit scoring
- House price prediction
- Medical diagnosis
Example in Pakistan:
A property website in Karachi might use supervised learning to predict house prices based on:
- Location
- Size
- Number of rooms
- Market trends
Unsupervised Learning
Unsupervised learning works with unlabeled data.
In this case, the algorithm does not know the correct answers.
Instead, it tries to discover patterns and relationships in the data.
Example dataset:
| Customer | Monthly Spending (PKR) |
|---|---|
| Ali | 5000 |
| Fatima | 5200 |
| Ahmad | 15000 |
| Sara | 16000 |
The algorithm might group customers into clusters:
Group 1:
- Ali
- Fatima
Group 2:
- Ahmad
- Sara
This helps businesses understand customer behavior.
Common unsupervised learning algorithms:
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN
- Principal Component Analysis (PCA)
Example in Pakistan:
A supermarket chain in Lahore might group customers based on purchasing behavior to create targeted marketing campaigns.
Key Components of Machine Learning
Machine learning models usually involve several important components.
Dataset
A dataset is a collection of data used to train models.
Example:
| Area (sq ft) | Price (PKR) |
|---|---|
| 1000 | 8,000,000 |
| 1200 | 9,500,000 |
| 1500 | 11,000,000 |
Features
Features are input variables used by the algorithm.
Example:
- Area
- Number of rooms
- Location
Labels
Labels are the correct answers in supervised learning.
Example:
House price.
Model
A model is the mathematical representation learned by the algorithm.
Training
Training means teaching the model using historical data.
Prediction
Prediction means using the model to estimate new outcomes.
Practical Code Examples
Let's now look at real machine learning examples using Python.
Example 1: Predicting Student Exam Scores
This example uses Linear Regression, one of the simplest ML algorithms.
Goal:
Predict exam scores based on study hours.
import numpy as np
from sklearn.linear_model import LinearRegression
# Study hours
hours = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
# Exam scores
scores = np.array([40, 50, 60, 70, 80])
# Create model
model = LinearRegression()
# Train model
model.fit(hours, scores)
# Predict score for 6 study hours
prediction = model.predict([[6]])
print(prediction)
Line-by-line explanation:
import numpy as np
This imports the NumPy library, used for handling arrays and numerical data.
from sklearn.linear_model import LinearRegression
This imports the Linear Regression algorithm from the Scikit-learn machine learning library.
hours = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
This creates a dataset representing study hours.
scores = np.array([40, 50, 60, 70, 80])
This creates the exam score dataset.
model = LinearRegression()
This initializes the machine learning model.
model.fit(hours, scores)
This trains the model using the dataset.
prediction = model.predict([[6]])
This predicts the exam score for 6 study hours.
print(prediction)
This displays the predicted score.
This is a supervised learning example because we already know the correct answers.
Example 2: Real-World Application (Customer Segmentation)
This example uses K-Means clustering, a common unsupervised learning algorithm.
Goal:
Group customers based on spending habits.
import numpy as np
from sklearn.cluster import KMeans
# Customer spending data
data = np.array([
[5000],
[5200],
[15000],
[16000],
[15500],
[4800]
])
# Create model with 2 clusters
kmeans = KMeans(n_clusters=2)
# Train the model
kmeans.fit(data)
# Display cluster labels
print(kmeans.labels_)
Line-by-line explanation:
import numpy as np
Imports the NumPy library for handling arrays.
from sklearn.cluster import KMeans
Imports the K-Means clustering algorithm.
data = np.array([...])
This dataset represents customer monthly spending in PKR.
kmeans = KMeans(n_clusters=2)
This creates a clustering model with 2 groups.
kmeans.fit(data)
This trains the model and finds clusters.
print(kmeans.labels_)
This displays which cluster each customer belongs to.
Businesses in Pakistan can use this technique to:
- Identify premium customers
- Offer personalized promotions
- Improve marketing strategies
Common Mistakes & How to Avoid Them
Mistake 1: Using Too Little Data
Machine learning models need enough data to learn patterns.
Bad example:
Study hours: [1,2]
Scores: [40,80]
This dataset is too small.
Solution:
Collect more data.
Example:
Study hours: [1,2,3,4,5,6,7,8]
Scores: [40,50,60,70,80,85,90,95]
More data improves accuracy.
Mistake 2: Ignoring Data Cleaning
Real-world datasets often contain:
- Missing values
- Incorrect entries
- Duplicate data
Example:
[5000, 5200, None, 16000]
Solution:
Clean the dataset before training.
Example:
import pandas as pd
data = pd.Series([5000, 5200, None, 16000])
clean_data = data.dropna()
print(clean_data)
Line-by-line explanation:
import pandas as pd
Imports the Pandas library for data processing.
data = pd.Series([...])
Creates a dataset with a missing value.
clean_data = data.dropna()
Removes missing values.
print(clean_data)
Displays the cleaned dataset.
Practice Exercises
Exercise 1: Predict House Prices
Problem:
Ahmad collects housing data in Islamabad.
| Area (sq ft) | Price (PKR) |
|---|---|
| 1000 | 8,000,000 |
| 1200 | 9,000,000 |
| 1500 | 11,000,000 |
Build a simple linear regression model to predict price.
Solution:
import numpy as np
from sklearn.linear_model import LinearRegression
area = np.array([1000, 1200, 1500]).reshape(-1,1)
price = np.array([8000000, 9000000, 11000000])
model = LinearRegression()
model.fit(area, price)
prediction = model.predict([[1300]])
print(prediction)
Exercise 2: Group Students by Marks
Problem:
Fatima wants to group students into high-performing and low-performing clusters.
Marks dataset:
[45, 50, 55, 85, 90, 95]
Solution:
import numpy as np
from sklearn.cluster import KMeans
marks = np.array([[45],[50],[55],[85],[90],[95]])
kmeans = KMeans(n_clusters=2)
kmeans.fit(marks)
print(kmeans.labels_)
This will group students based on similar scores.
Frequently Asked Questions
What is machine learning?
Machine learning is a branch of artificial intelligence where computers learn patterns from data instead of being explicitly programmed. It allows software to improve automatically with experience.
What is supervised learning?
Supervised learning is a machine learning method where the model learns from labeled data. Each training example includes the correct answer, helping the algorithm make accurate predictions.
What is unsupervised learning?
Unsupervised learning works with unlabeled data. The algorithm identifies hidden patterns or groups in the data without knowing the correct output beforehand.
Which programming language is best for machine learning?
Python is the most popular language for machine learning because it has powerful libraries like NumPy, Pandas, and Scikit-learn that simplify data analysis and model building.
How long does it take to learn machine learning?
Beginners can understand machine learning basics in a few weeks. However, mastering ML algorithms and building real-world projects usually takes several months of practice.
Summary & Key Takeaways
- Machine learning allows computers to learn patterns from data.
- Supervised learning uses labeled data to make predictions.
- Unsupervised learning discovers patterns in unlabeled data.
- Popular ML algorithms include Linear Regression, Decision Trees, and K-Means.
- Python libraries like NumPy, Pandas, and Scikit-learn make ML easier.
- Real-world applications include fraud detection, recommendation systems, and customer segmentation.
Next Steps & Related Tutorials
If you want to continue learning machine learning, these tutorials on theiqra.edu.pk will help you go deeper:
- Learn Python for Data Science to build a strong programming foundation.
- Explore NumPy Tutorial for Beginners to understand numerical computing.
- Study Pandas Data Analysis Guide to work with real-world datasets.
- Continue with Introduction to Data Science to learn how ML fits into the data science workflow.
These tutorials will prepare you for more advanced topics such as deep learning, neural networks, and artificial intelligence systems.
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.