MLOps Tutorial ML Pipelines Versioning & Monitoring
Introduction
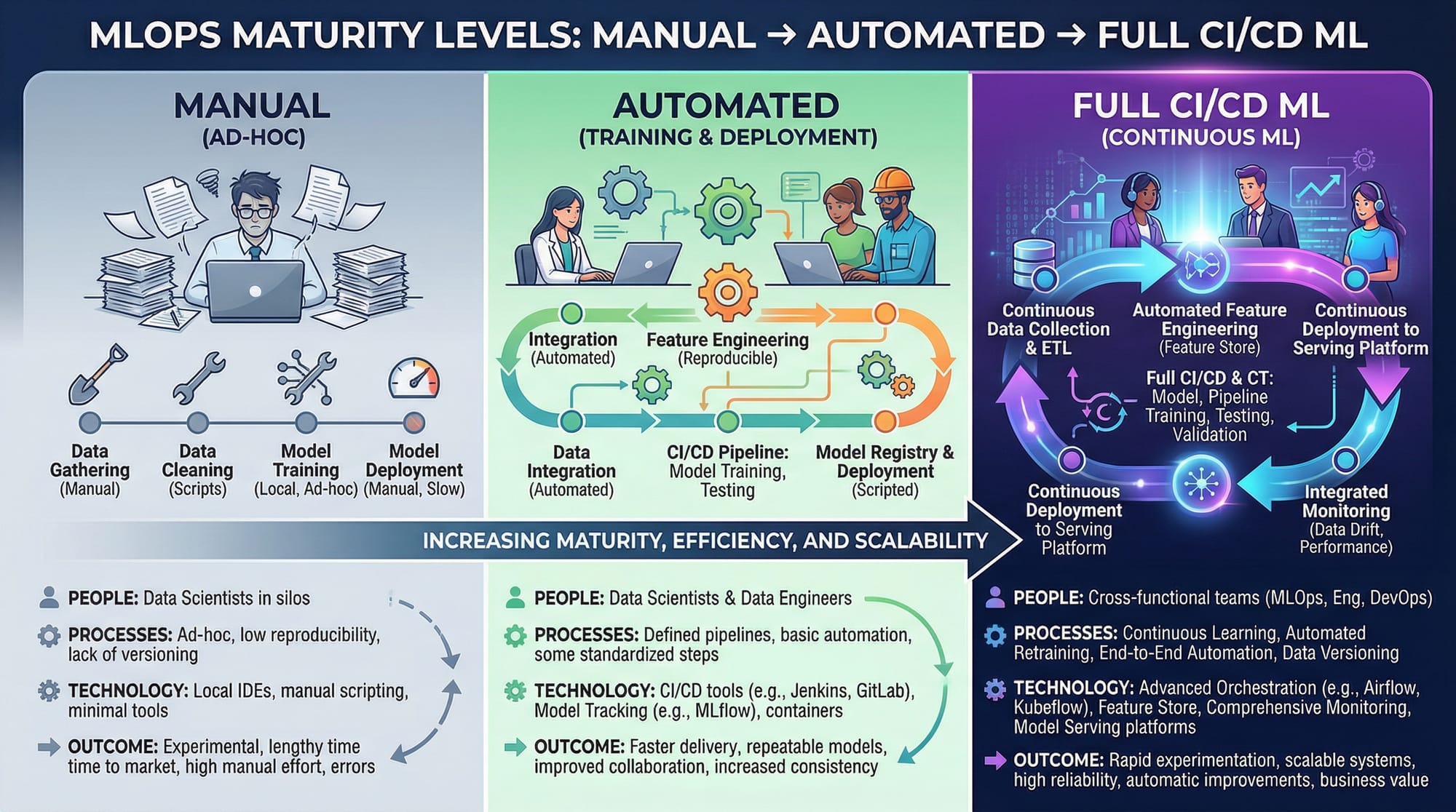
Machine Learning has moved far beyond building models in notebooks. Today, real-world success depends on how efficiently models are deployed, monitored, and maintained. This is where MLOps (Machine Learning Operations) comes in.
In this mlops tutorial: ml pipelines, versioning & monitoring, you’ll learn how to build production-ready machine learning systems using structured pipelines, proper version control, and monitoring strategies.
For Pakistani students in cities like Lahore, Karachi, and Islamabad, learning MLOps is especially valuable. Companies in fintech, e-commerce, and healthcare are actively hiring engineers who can not only build models but also deploy and maintain them at scale. Whether you are Ahmad building a fraud detection system or Fatima working on a recommendation engine, MLOps skills will make your work industry-ready.
Prerequisites
Before starting this mlops tutorial, you should have:
- Strong understanding of Python
- Basic knowledge of Machine Learning (e.g., regression, classification)
- Familiarity with libraries like
scikit-learn,pandas, andnumpy - Basic understanding of Git (version control)
- Some exposure to APIs (Flask or FastAPI is a plus)
- Optional but helpful: Docker and cloud platforms
Core Concepts & Explanation
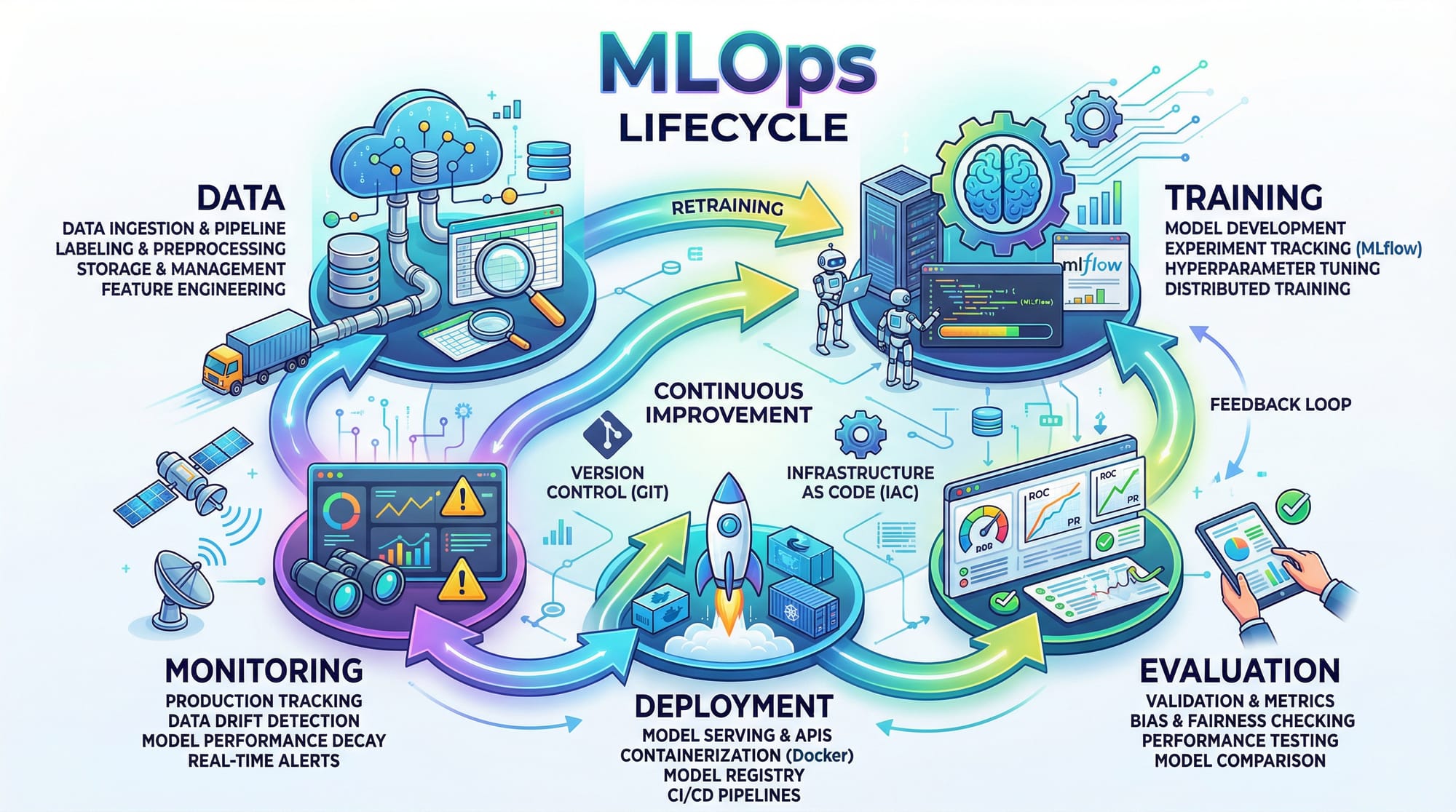
ML Pipelines: Automating the Workflow
An ML pipeline is a structured sequence of steps that automate the machine learning workflow.
Typical pipeline stages:
- Data ingestion
- Data preprocessing
- Model training
- Evaluation
- Deployment
Example:
Ali is building a house price prediction model for Karachi. Instead of manually running scripts, he creates a pipeline that:
- Loads data from CSV
- Cleans missing values
- Trains a model
- Evaluates accuracy
This ensures consistency and reproducibility.
Why pipelines matter:
- Reduce human errors
- Enable automation
- Make workflows reusable
Model Versioning: Tracking Changes Like Code
Just like software code, ML models also need versioning.
What to version:
- Dataset versions
- Model parameters
- Training code
- Metrics
Example:
Fatima trains two models:
- Model A → accuracy: 85%
- Model B → accuracy: 90%
Without versioning, she cannot track which dataset or parameters led to better performance.
Tools used:
- MLflow
- DVC (Data Version Control)
- Git
Monitoring: Keeping Models Healthy in Production
Once deployed, models can degrade over time due to data drift.
Example:
Ahmad deploys a loan prediction model in Islamabad. Over time:
- User behavior changes
- Economic conditions shift
Result: Model accuracy drops.
Monitoring helps:
- Track performance metrics
- Detect drift
- Trigger retraining
Practical Code Examples
Example 1: Building a Simple ML Pipeline with Scikit-learn
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
# Train model
pipeline.fit(X_train, y_train)
# Evaluate
accuracy = pipeline.score(X_test, y_test)
print("Accuracy:", accuracy)
Line-by-line explanation:
from sklearn.pipeline import Pipeline→ Imports pipeline functionalityStandardScaler()→ Normalizes dataLogisticRegression()→ ML modeltrain_test_split()→ Splits data into training/testingPipeline([...])→ Defines sequential stepsfit()→ Trains pipelinescore()→ Evaluates model
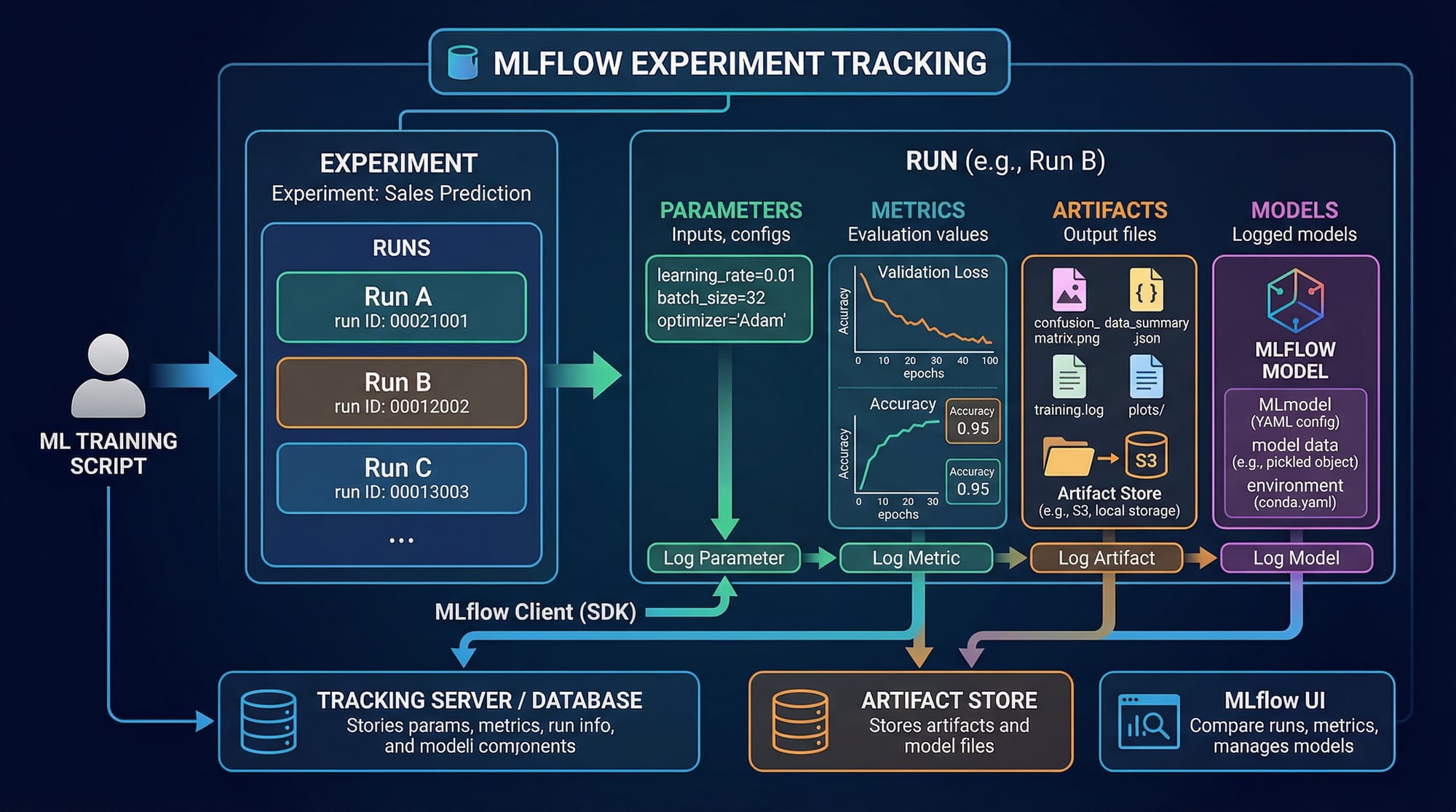
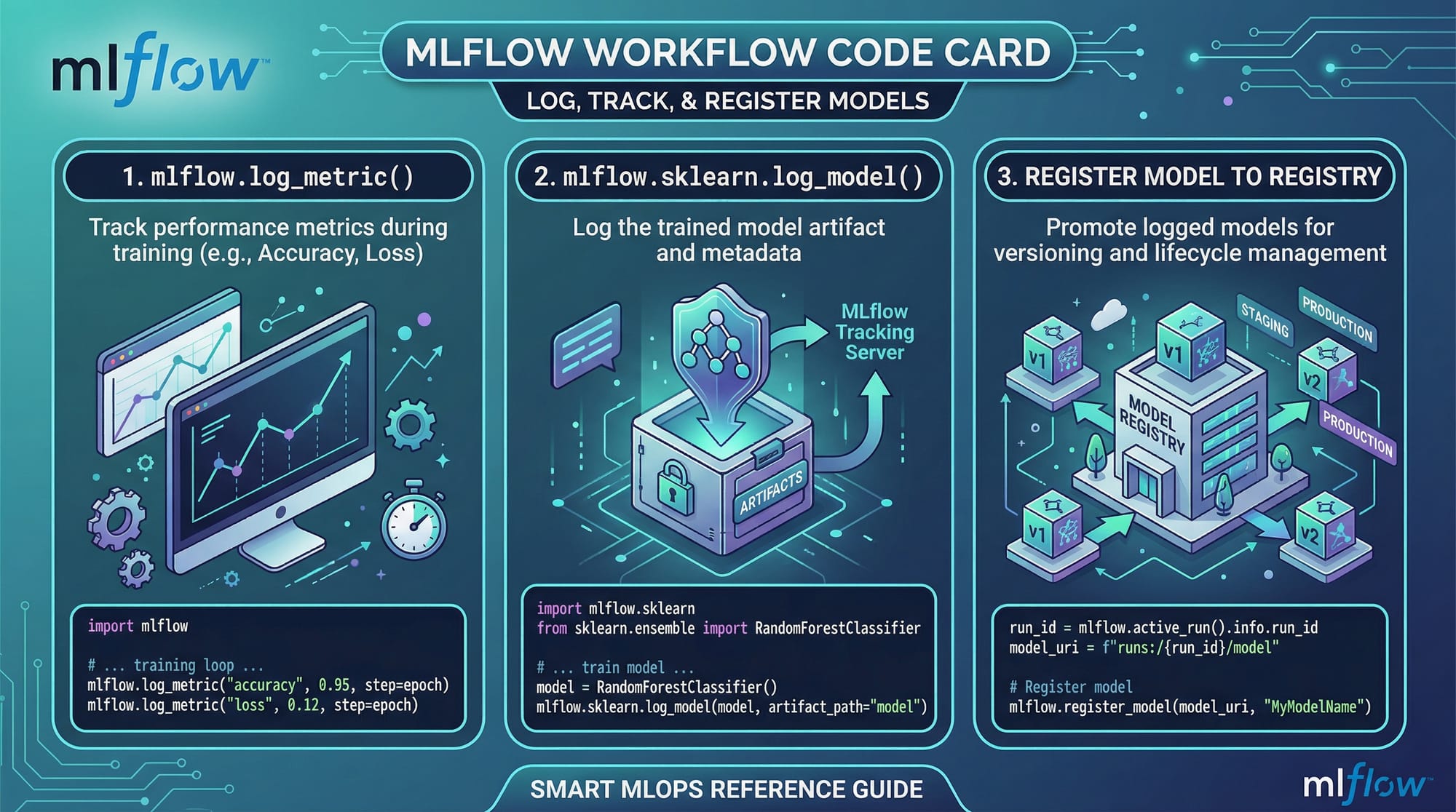
Example 2: Real-World Application Using MLflow
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Load data
X, y = load_iris(return_X_y=True)
# Start MLflow run
with mlflow.start_run():
# Train model
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
# Log parameters
mlflow.log_param("n_estimators", 100)
# Log metrics
accuracy = model.score(X, y)
mlflow.log_metric("accuracy", accuracy)
# Log model
mlflow.sklearn.log_model(model, "model")
Line-by-line explanation:
import mlflow→ Imports MLflowstart_run()→ Starts experiment trackingRandomForestClassifier()→ Creates modelfit()→ Trains modellog_param()→ Stores parameterslog_metric()→ Saves performance metricslog_model()→ Stores trained model
Common Mistakes & How to Avoid Them
Mistake 1: No Version Control for Data
Many beginners only version code but ignore data.
Problem:
Model results become inconsistent.
Fix:
- Use DVC or MLflow
- Store dataset versions
Mistake 2: Ignoring Model Monitoring
Students often stop after deployment.
Problem:
Model performance drops silently.
Fix:
- Track metrics in real time
- Set alerts for accuracy drops
- Retrain models periodically
Practice Exercises
Exercise 1: Build a Pipeline
Problem:
Create a pipeline for a classification dataset using scaling and logistic regression.
Solution:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
Exercise 2: Track Experiment with MLflow
Problem:
Log model accuracy and parameters using MLflow.
Solution:
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.92)
Frequently Asked Questions
What is MLOps?
MLOps is a set of practices that combines machine learning, DevOps, and data engineering to automate and manage ML systems in production.
How do I deploy an ML model?
You can deploy models using APIs (Flask/FastAPI), Docker containers, or cloud platforms like AWS and Azure.
Why is versioning important in ML?
Versioning helps track changes in data, models, and code, ensuring reproducibility and better debugging.
What tools are used in MLOps?
Common tools include MLflow, DVC, Kubeflow, Docker, and CI/CD pipelines.
How do I monitor ML models?
You can monitor models using dashboards, logging tools, and alert systems to track performance and detect drift.
Summary & Key Takeaways
- MLOps is essential for real-world machine learning deployment
- ML pipelines automate and standardize workflows
- Versioning ensures reproducibility and better collaboration
- Monitoring helps detect model performance issues early
- Tools like MLflow make tracking and deployment easier
- Pakistani students can gain a strong career advantage by learning MLOps
Next Steps & Related Tutorials
To continue your journey, explore these tutorials on theiqra.edu.pk:
- Learn ML Model Deployment to serve your models via APIs
- Explore a complete DevOps Tutorial to understand CI/CD pipelines
- Dive into Docker for Beginners to containerize ML applications
- Study Data Engineering Basics to build robust data pipelines
These topics will help you become a complete machine learning engineer ready for industry roles in Pakistan and beyond 🚀
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.