Natural Language Processing (NLP) & Text Analysis
Introduction
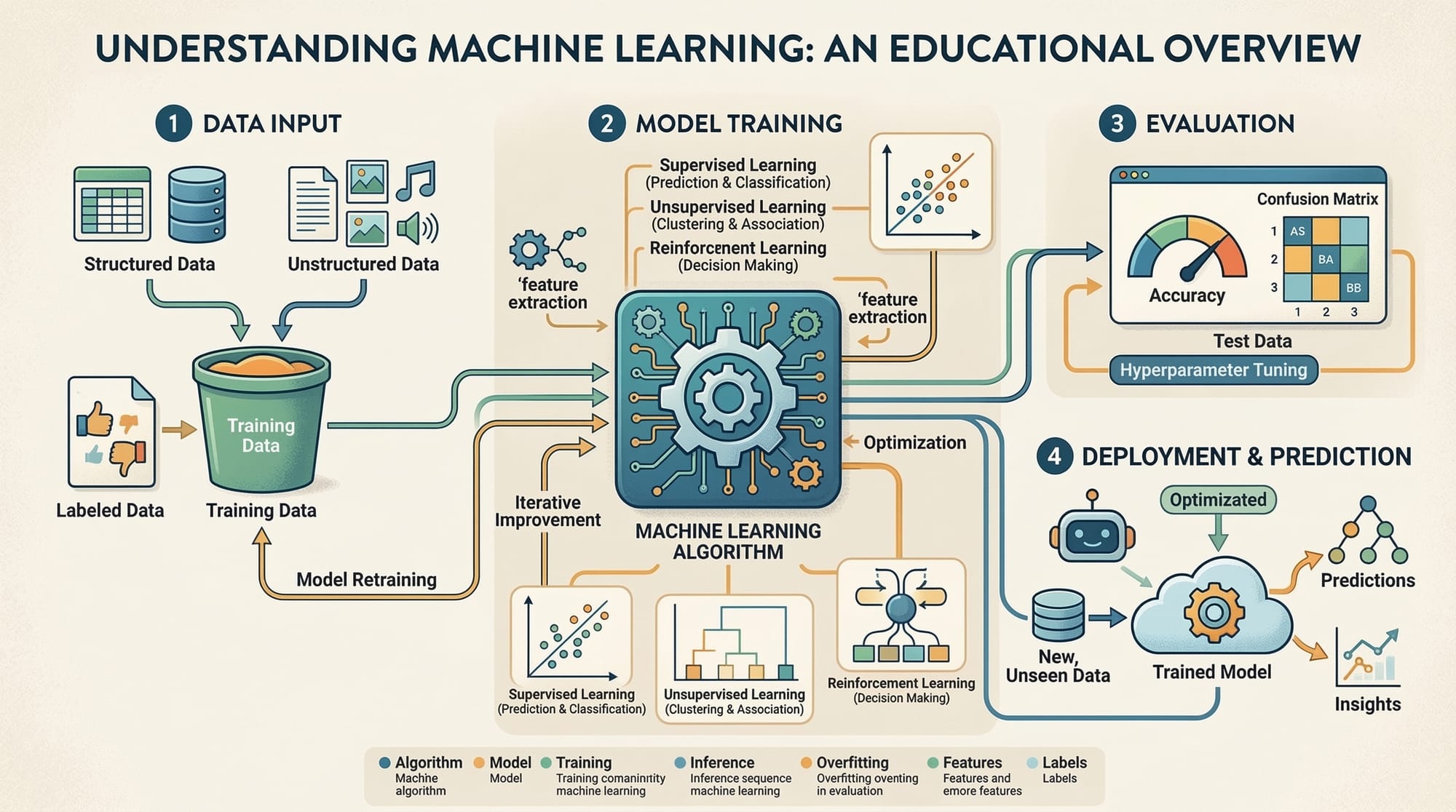
Natural Language Processing (NLP) is one of the most exciting fields in modern Artificial Intelligence (AI). It focuses on enabling computers to understand, interpret, and generate human language. In simple terms, Natural Language Processing (NLP) helps machines understand text and speech the same way humans do.
Every day, we interact with systems powered by nlp and text analysis without realizing it. When you ask a question to a chatbot, search something on Google, translate Urdu to English, or analyze customer reviews — natural language processing is working behind the scenes.
For Pakistani students learning programming and machine learning, understanding nlp basics opens the door to many practical applications such as:
- Sentiment analysis of product reviews
- Urdu text classification
- Chatbots for university websites
- Fake news detection
- Customer feedback analysis
For example, imagine Ahmad, a student in Lahore, who builds a simple system to analyze restaurant reviews. The system can automatically determine whether a review is positive or negative using sentiment analysis. Businesses in Karachi or Islamabad could use this to understand customer satisfaction.
Similarly, Fatima, a data science student, might analyze Twitter posts about electricity prices or university admissions to identify public opinion.
This tutorial will guide you step-by-step through Natural Language Processing (NLP) & Text Analysis, including concepts, practical examples, and real-world applications relevant to Pakistani students.
By the end of this guide, you will understand:
- What NLP is and how it works
- Important text analysis techniques
- How to build sentiment analysis systems
- How to process and analyze text using Python
Prerequisites
Before learning Natural Language Processing (NLP), you should have some basic knowledge of programming and data science concepts.
Here are the recommended prerequisites:
1. Basic Python Programming
You should understand:
- Variables
- Lists and dictionaries
- Loops
- Functions
Example:
text = "Pakistan is learning AI"
print(text.lower())
Explanation:
text = "Pakistan is learning AI"
This line creates a variable called text containing a string.
print(text.lower())
The .lower() function converts all characters into lowercase.
2. Basic Machine Learning Concepts
You should understand:
- Training data
- Features
- Models
- Predictions
Example concept:
If a model learns that “excellent”, “good”, “amazing” appear in positive reviews, it can predict whether a new review is positive.
3. Basic Understanding of Data
NLP works with text data, such as:
- Reviews
- Emails
- Tweets
- News articles
- Chat messages
Example dataset:
| Review | Sentiment |
|---|---|
| Food was amazing | Positive |
| Service was slow | Negative |
4. Python Libraries (Helpful)
You should be familiar with:
numpypandasscikit-learn
For NLP specifically:
nltkspacytransformers
Core Concepts & Explanation
Text Preprocessing in NLP
Before analyzing text, we must clean and prepare it. This step is called text preprocessing.
Raw text usually contains:
- punctuation
- uppercase letters
- irrelevant words
- extra spaces
Example raw text:
"The food in Lahore was AMAZING!!!"
After preprocessing:
food lahore amazing
Common preprocessing steps include:
- Lowercasing
- Removing punctuation
- Tokenization
- Stopword removal
- Stemming or lemmatization
Example using Python:
import nltk
from nltk.tokenize import word_tokenize
text = "Ali is studying Natural Language Processing in Islamabad."
tokens = word_tokenize(text)
print(tokens)
Explanation:
import nltk
Imports the Natural Language Toolkit, a popular NLP library.
from nltk.tokenize import word_tokenize
Imports a function that splits text into words.
text = "Ali is studying Natural Language Processing in Islamabad."
Creates a text string.
tokens = word_tokenize(text)
Breaks the sentence into individual words.
print(tokens)
Displays the list of tokens.
Output:
['Ali', 'is', 'studying', 'Natural', 'Language', 'Processing', 'in', 'Islamabad', '.']
Tokenization & Text Representation
Computers cannot understand words directly. We must convert text into numbers.
This process is called text representation.
Two common methods:
- Bag of Words
- TF-IDF
Example sentence:
Karachi is a big city
Tokenized version:
["karachi", "is", "a", "big", "city"]
Bag-of-Words representation:
| Word | Count |
|---|---|
| karachi | 1 |
| city | 1 |
| big | 1 |
Example Python code:
from sklearn.feature_extraction.text import CountVectorizer
documents = [
"Lahore is beautiful",
"Karachi is a big city"
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
print(X.toarray())
Explanation:
CountVectorizer()
Creates a tool that converts text into numeric vectors.
fit_transform(documents)
Learns vocabulary and transforms documents.
print(X.toarray())
Displays the numeric representation.
Practical Code Examples
Example 1: Simple Sentiment Analysis
Let’s build a basic sentiment analysis model.
Imagine we want to classify restaurant reviews in Pakistan.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
reviews = [
"Food was excellent",
"Service was terrible",
"Amazing taste",
"Very bad experience"
]
labels = ["positive", "negative", "positive", "negative"]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(reviews)
model = MultinomialNB()
model.fit(X, labels)
test_review = ["Food was amazing"]
test_vector = vectorizer.transform(test_review)
prediction = model.predict(test_vector)
print(prediction)
Explanation:
from sklearn.feature_extraction.text import CountVectorizer
Imports a tool to convert text into numbers.
from sklearn.naive_bayes import MultinomialNB
Imports a machine learning model used for text classification.
reviews = [...]
Creates sample review data.
labels = [...]
Specifies whether each review is positive or negative.
vectorizer = CountVectorizer()
Creates the text vectorizer.
X = vectorizer.fit_transform(reviews)
Converts reviews into numeric vectors.
model = MultinomialNB()
Creates the classification model.
model.fit(X, labels)
Trains the model.
test_review = ["Food was amazing"]
New review for prediction.
prediction = model.predict(test_vector)
Predicts sentiment.
Output:
positive
Example 2: Real-World Application
Let’s analyze student feedback for a university course.
feedback = [
"The course was very helpful",
"The lectures were boring",
"I learned a lot",
"Too difficult and confusing"
]
positive_words = ["helpful", "learned"]
negative_words = ["boring", "difficult", "confusing"]
for comment in feedback:
score = 0
for word in positive_words:
if word in comment:
score += 1
for word in negative_words:
if word in comment:
score -= 1
if score > 0:
sentiment = "Positive"
else:
sentiment = "Negative"
print(comment, "->", sentiment)
Explanation:
feedback = [...]
List of student comments.
positive_words and negative_words
Define sentiment indicators.
for comment in feedback:
Loops through each feedback entry.
score = 0
Initial sentiment score.
if word in comment:
Checks if certain words appear.
score += 1
Adds positive score.
score -= 1
Subtracts for negative words.
print(comment, "->", sentiment)
Displays sentiment classification.
Common Mistakes & How to Avoid Them
Mistake 1: Ignoring Text Preprocessing
Many beginners skip preprocessing.
Example problem:
Amazing
amazing
AMAZING
These appear as three different words to the model.
Solution:
text = text.lower()
This converts everything into lowercase.
Mistake 2: Using Too Little Training Data
Machine learning models need large datasets.
Example mistake:
Training a sentiment model with only 5 reviews.
Solution:
Use datasets with thousands of examples, such as:
- Twitter data
- Product reviews
- News datasets
Practice Exercises
Exercise 1: Word Frequency Counter
Problem:
Write Python code that counts the frequency of words in the sentence:
"Pakistan is learning AI and Pakistan is growing in technology"
Solution:
from collections import Counter
text = "Pakistan is learning AI and Pakistan is growing in technology"
words = text.split()
count = Counter(words)
print(count)
Explanation:
Counter
Counts occurrences of each word.
split()
Breaks the sentence into words.
Counter(words)
Calculates word frequency.
Exercise 2: Simple Sentiment Detector
Problem:
Classify the sentence as positive or negative using keyword lists.
Solution:
sentence = "The restaurant food was amazing"
positive = ["amazing", "good", "excellent"]
negative = ["bad", "terrible"]
score = 0
for word in positive:
if word in sentence:
score += 1
for word in negative:
if word in sentence:
score -= 1
print(score)
Explanation:
Each positive word increases the score, while negative words reduce it.
Frequently Asked Questions
What is Natural Language Processing (NLP)?
Natural Language Processing is a field of artificial intelligence that enables computers to understand, interpret, and generate human language. It is widely used in chatbots, translation systems, and sentiment analysis.
How do I start learning NLP?
Start with Python and libraries like NLTK, spaCy, and scikit-learn. Learn text preprocessing, tokenization, and basic machine learning models before moving to advanced NLP techniques.
What is sentiment analysis?
Sentiment analysis is an NLP technique that determines whether text expresses a positive, negative, or neutral opinion. It is commonly used to analyze customer reviews and social media posts.
Can NLP work with Urdu language?
Yes. NLP can process Urdu text, but it may require specialized datasets and preprocessing techniques. Libraries like spaCy and Hugging Face Transformers support multilingual models.
Is NLP used in real companies?
Yes. Companies use NLP for chatbots, voice assistants, customer support automation, spam filtering, and recommendation systems.
Summary & Key Takeaways
- Natural Language Processing (NLP) enables computers to understand human language.
- Text preprocessing is an essential step before analyzing text.
- Techniques like tokenization and Bag-of-Words convert text into numerical form.
- Sentiment analysis helps classify opinions in reviews and feedback.
- Python libraries such as NLTK and scikit-learn simplify NLP implementation.
- NLP skills can lead to careers in AI, machine learning, and data science.
Next Steps & Related Tutorials
To continue learning Machine Learning and NLP, explore these tutorials on theiqra.edu.pk:
- Learn the fundamentals of Machine Learning Basics
- Understand Deep Learning & Convolutional Neural Networks
- Improve database knowledge with SQL Joins Tutorial
- Master Neural Networks Explained
These tutorials will help you build stronger foundations before moving into advanced NLP topics like transformers, BERT, and large language models.
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.