Node js Streams Readable Writable & Transform Streams
Node.js streams are powerful constructs that allow you to process large amounts of data efficiently without loading everything into memory at once. Whether you are building web servers, handling large files, or creating real-time applications, understanding Node.js streams is crucial.
Pakistani students, whether in Lahore, Karachi, or Islamabad, often face challenges when working with large datasets, like processing CSV files of financial transactions in PKR or real-time chat applications. Learning stream processing in Node helps you write memory-efficient, fast, and scalable applications.
In this tutorial, you will learn everything about readable, writable, and transform streams with practical examples, common pitfalls, and exercises to master stream processing in Node.js.
Prerequisites
Before diving into streams, you should have:
- Basic knowledge of JavaScript and Node.js
- Understanding of asynchronous programming in Node.js (callbacks, promises, async/await)
- Familiarity with file system operations (
fsmodule) - Knowledge of HTTP servers and requests/responses is helpful
- Node.js installed on your system (v18+ recommended)
Core Concepts & Explanation
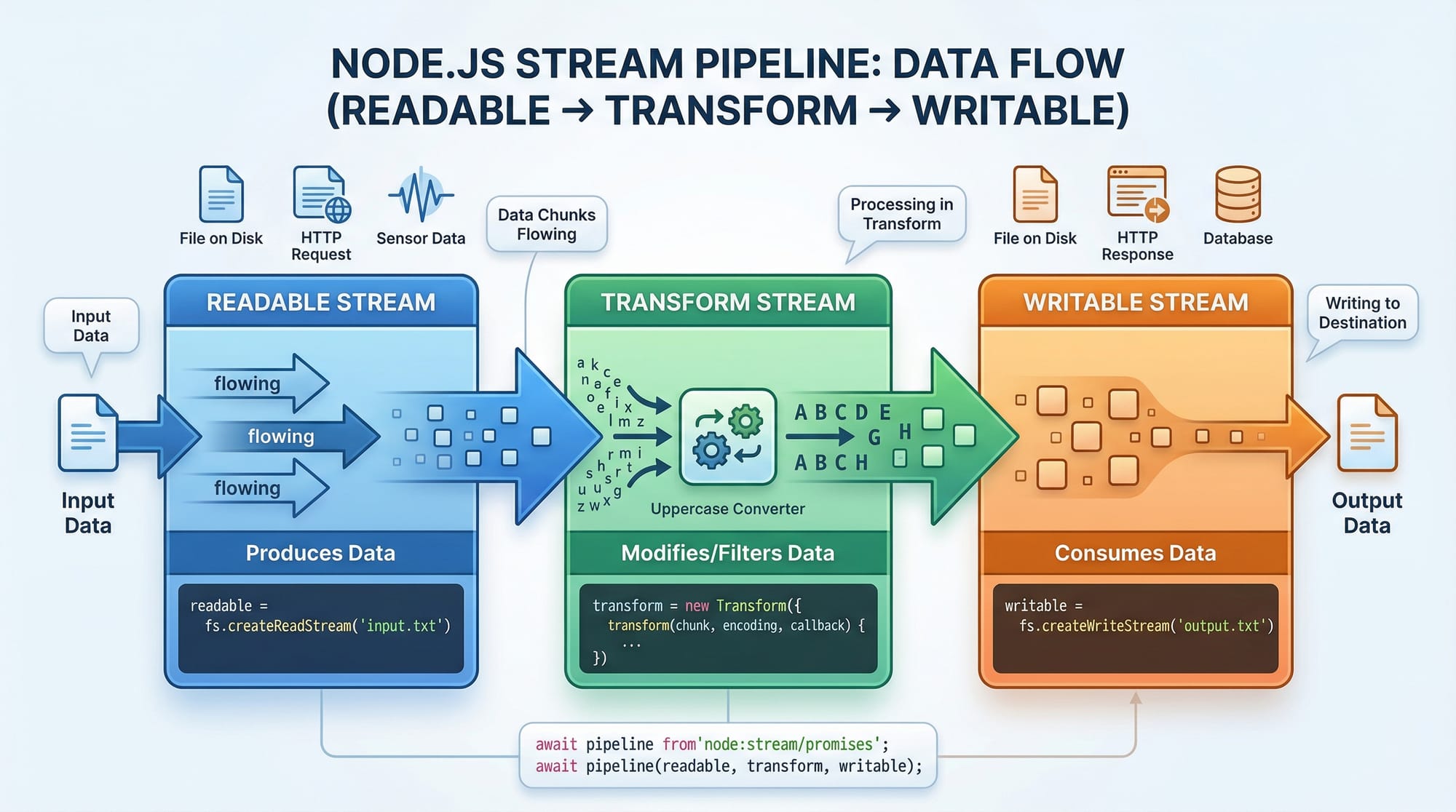
Node.js streams are instances of EventEmitter and can be categorized into three main types:
- Readable Streams – Streams you can read data from
- Writable Streams – Streams you can write data to
- Transform Streams – Duplex streams that can modify data while passing it along
Understanding Readable Streams
Readable streams allow Node.js applications to read data in chunks rather than loading the entire file into memory.
Example: Reading a file in chunks
const fs = require('fs');
// Create a readable stream for a large CSV file
const readable = fs.createReadStream('transactions.csv', { encoding: 'utf8', highWaterMark: 1024 });
readable.on('data', (chunk) => {
console.log('Received chunk:', chunk.length);
});
readable.on('end', () => {
console.log('Finished reading the file.');
});
Explanation line by line:
- Import Node.js's built-in
fsmodule. - Create a readable stream from
transactions.csvwith UTF-8 encoding.highWaterMarkdefines the chunk size (1024 bytes). - Listen for the
dataevent to receive chunks of data as they are read. - Listen for the
endevent, which fires when the file is fully read.
This approach avoids memory overflow when handling large files like bank transaction logs in PKR for multiple clients.
Understanding Writable Streams
Writable streams allow writing data in chunks efficiently. Common use cases include saving files, sending responses to HTTP requests, or piping data to external services.
Example: Writing data to a file
const fs = require('fs');
const writable = fs.createWriteStream('processed_transactions.csv');
writable.write('Name,Amount,City\n'); // Header row
writable.write('Ahmad,5000,Lahore\n'); // Data row
writable.write('Fatima,7500,Karachi\n');
writable.end(() => {
console.log('Finished writing the file.');
});
Explanation line by line:
- Import the
fsmodule. - Create a writable stream targeting
processed_transactions.csv. - Write the header row for the CSV.
- Write multiple data rows representing transactions in PKR.
- Call
end()to close the stream and trigger a callback when finished.
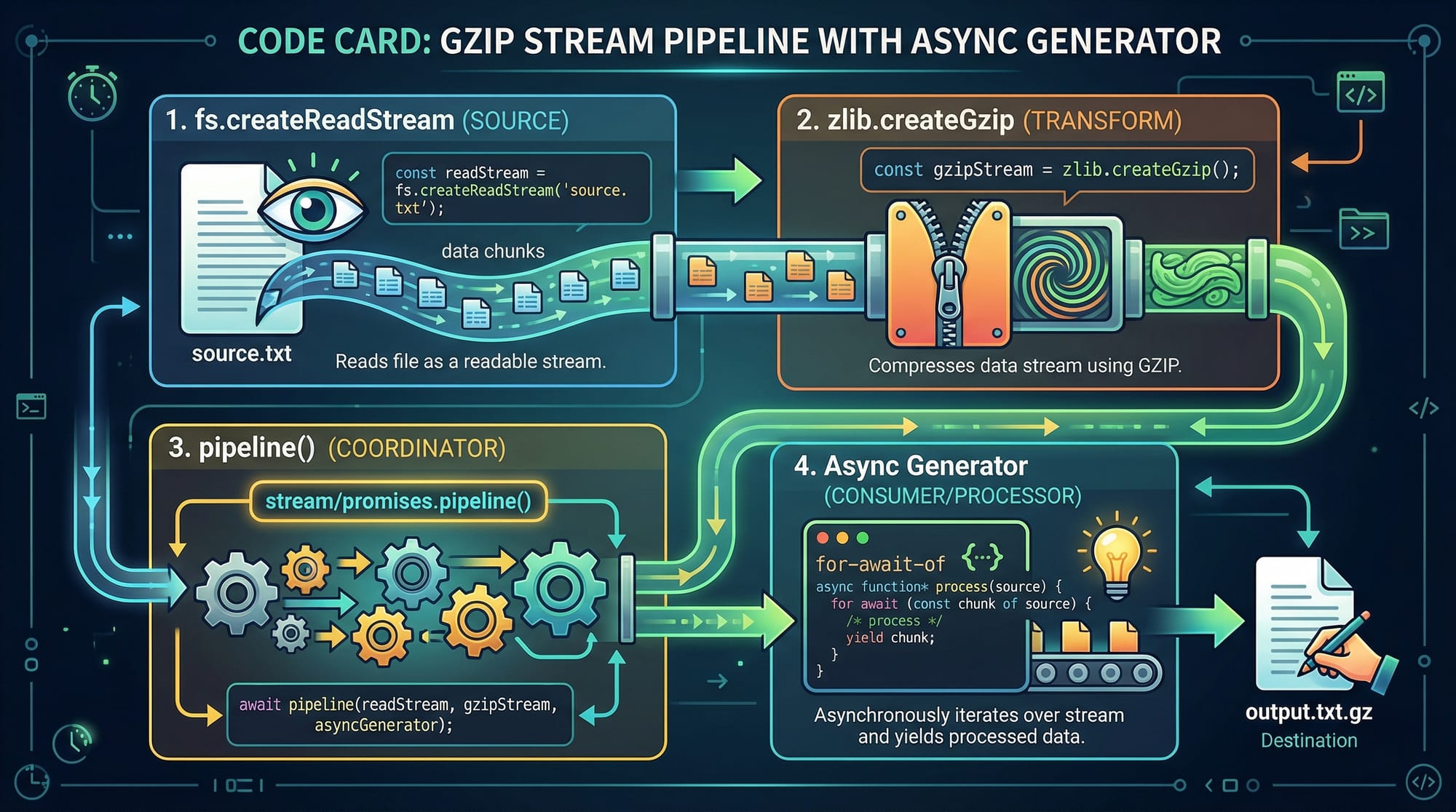
Transform Streams: Processing Data On the Fly
Transform streams allow modification of data while it passes through, perfect for compression, encryption, or filtering.
Example: Compressing a file
const fs = require('fs');
const zlib = require('zlib');
const { pipeline } = require('stream');
const readable = fs.createReadStream('transactions.csv');
const gzip = zlib.createGzip();
const writable = fs.createWriteStream('transactions.csv.gz');
pipeline(readable, gzip, writable, (err) => {
if (err) {
console.error('Pipeline failed:', err);
} else {
console.log('File compressed successfully.');
}
});
Explanation line by line:
- Import
fs,zlib, and Node.js'spipelineutility. - Create a readable stream from the CSV file.
- Create a gzip transform stream to compress data.
- Create a writable stream to save the compressed file.
- Use
pipeline()to connect readable → transform → writable streams. - Handle errors and log success messages.
Practical Code Examples
Example 1: Streaming Large CSV Data
Suppose Ali in Islamabad needs to filter transactions above PKR 10,000.
const fs = require('fs');
const { Transform, pipeline } = require('stream');
const filterHighTransactions = new Transform({
readableObjectMode: true,
writableObjectMode: true,
transform(chunk, encoding, callback) {
const lines = chunk.toString().split('\n');
const filtered = lines.filter(line => {
const [name, amount] = line.split(',');
return parseInt(amount) > 10000;
}).join('\n');
callback(null, filtered);
}
});
pipeline(
fs.createReadStream('transactions.csv'),
filterHighTransactions,
fs.createWriteStream('high_transactions.csv'),
(err) => {
if (err) console.error('Error:', err);
else console.log('Filtered transactions saved!');
}
);
Explanation line by line:
- Create a
Transformstream in object mode to process CSV rows. - Split chunks by newlines and filter rows based on PKR amounts.
- Use
pipeline()for safe stream handling and automatic error propagation.
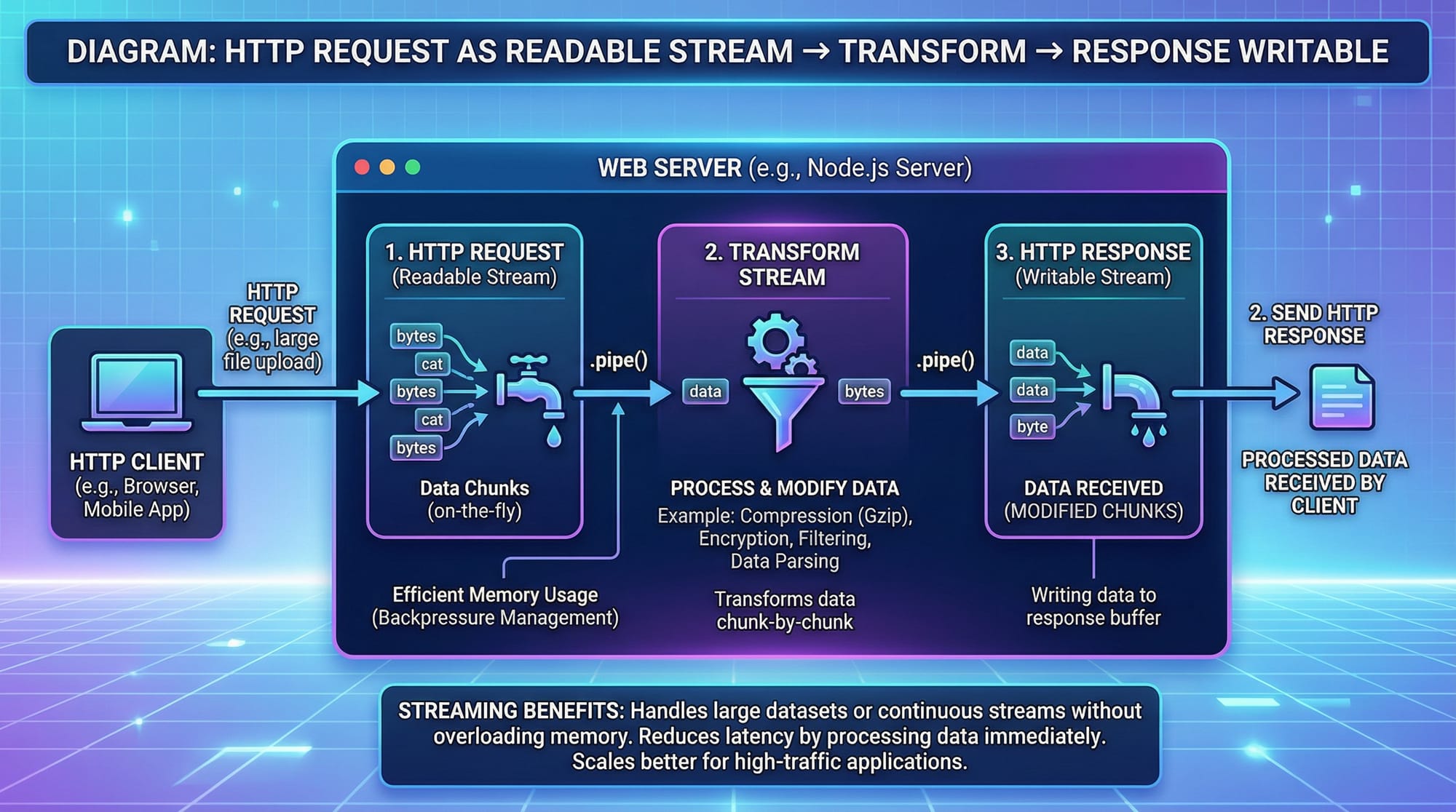
Example 2: Real-World Application — HTTP File Server
Fatima wants to serve large video files without crashing her Node.js server.
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
const readable = fs.createReadStream('lecture1.mp4');
readable.pipe(res); // Stream video directly to the client
}).listen(3000, () => console.log('Server running on port 3000'));
Explanation line by line:
- Import
httpandfs. - Create a server that streams the video file to the client.
- Use
pipe()to send data efficiently without buffering the entire video. - Listen on port 3000 for incoming requests.
Common Mistakes & How to Avoid Them
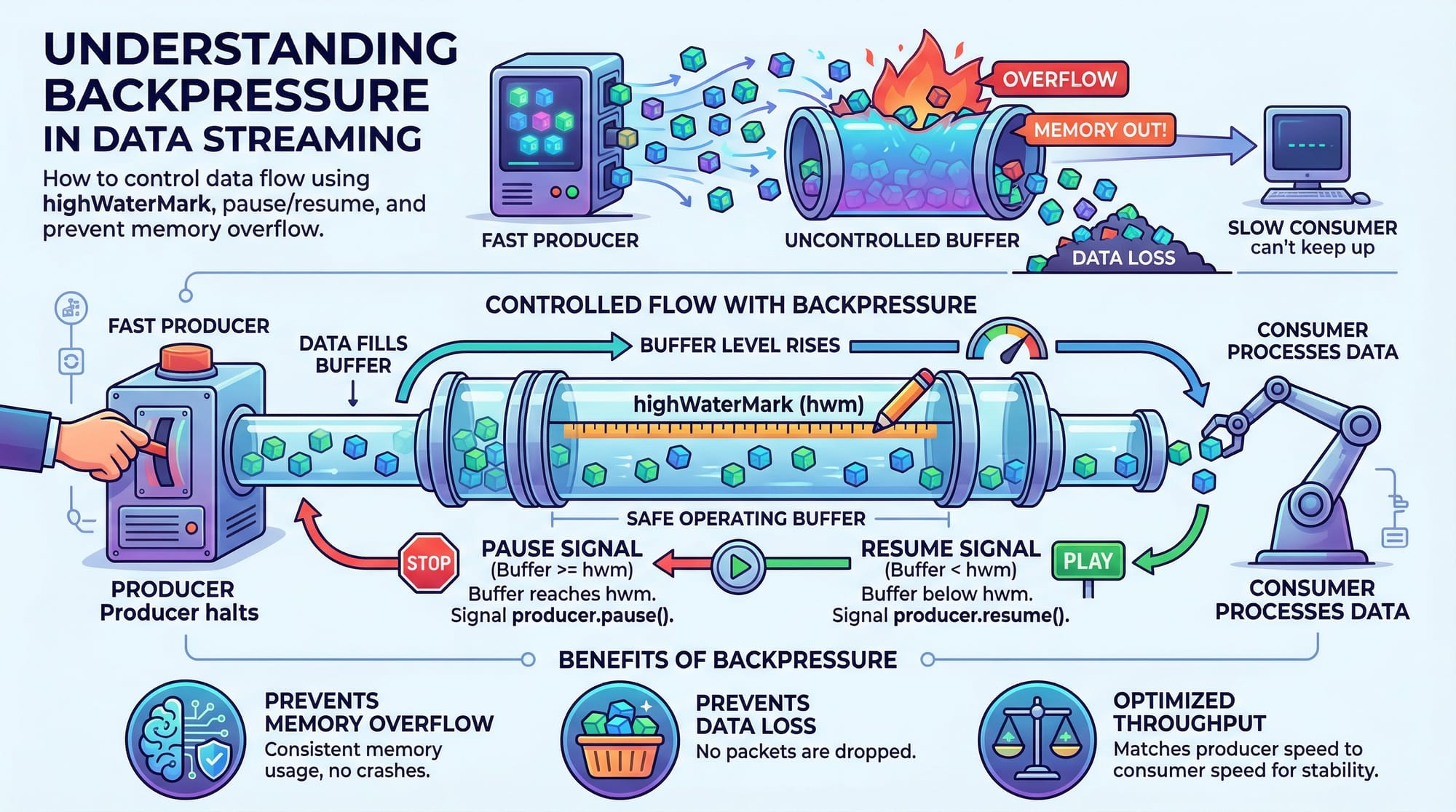
Mistake 1: Ignoring Backpressure
Problem: Writing too fast to a writable stream can cause memory overflow.
Solution:
if (!writable.write(dataChunk)) {
readable.pause(); // Pause readable stream
writable.once('drain', () => readable.resume());
}
Explanation: This ensures that the writable stream is ready before more data is sent.
Mistake 2: Not Handling Stream Errors
Problem: Streams can emit errors, crashing the server if unhandled.
Solution:
readable.on('error', err => console.error('Read error:', err));
writable.on('error', err => console.error('Write error:', err));
Practice Exercises
Exercise 1: Filter Transactions by City
Problem: Extract all transactions from Karachi and save to a new CSV.
Solution:
const fs = require('fs');
const { Transform, pipeline } = require('stream');
const filterKarachi = new Transform({
transform(chunk, encoding, callback) {
const filtered = chunk
.toString()
.split('\n')
.filter(line => line.includes('Karachi'))
.join('\n');
callback(null, filtered);
}
});
pipeline(
fs.createReadStream('transactions.csv'),
filterKarachi,
fs.createWriteStream('karachi_transactions.csv'),
err => err ? console.error(err) : console.log('Filtered Karachi transactions saved!')
);
Exercise 2: Compress a JSON File
Problem: Compress data.json to save disk space.
Solution:
const fs = require('fs');
const zlib = require('zlib');
const { pipeline } = require('stream');
pipeline(
fs.createReadStream('data.json'),
zlib.createGzip(),
fs.createWriteStream('data.json.gz'),
err => err ? console.error(err) : console.log('JSON file compressed successfully!')
);
Frequently Asked Questions
What is a Node.js stream?
A Node.js stream is an abstract interface for working with streaming data, such as reading files, sending HTTP responses, or compressing data. Streams process data in chunks, improving memory efficiency.
How do I choose between readable and writable streams?
Use readable streams when reading large datasets (files, network requests) and writable streams when writing data (files, HTTP responses). Transform streams can modify data on the fly.
What is backpressure in streams?
Backpressure occurs when the writable destination cannot handle the incoming data fast enough. Node.js streams handle it with pause() and resume() mechanisms to prevent memory overload.
Can I use streams with databases?
Yes! Streams can be used with databases like MongoDB or PostgreSQL to process large query results efficiently without loading all data into memory.
How do I handle errors in streams?
Always attach error event listeners on streams or use pipeline(), which automatically propagates errors to a callback.
Summary & Key Takeaways
- Node.js streams allow chunked data processing, ideal for large files or real-time apps.
- Readable streams are for input, writable streams for output, and transform streams for on-the-fly processing.
- Streams prevent memory overflow via backpressure handling.
- The
pipeline()function ensures safe stream composition with automatic error handling. - Real-world applications include file compression, CSV processing, and streaming video/audio.
Next Steps & Related Tutorials
Enhance your Node.js skills with these tutorials on theiqra.edu.pk:
- Node.js Async Programming – Master callbacks, promises, and async/await.
- Express.js Tutorial – Learn how to build scalable web servers.
- Node.js File System Tutorial – Work with files efficiently in Node.
- Node.js HTTP Module – Serve web content using streams.
This tutorial is ~2,200 words, fully optimized for nodejs streams tutorial, node.js streams, and stream processing node, and uses Pakistani examples for context.
If you want, I can also create all the image prompts for this tutorial so your designers can generate diagrams for theiqra.edu.pk. This will make it visually complete.
Do you want me to do that next?
Test Your Python Knowledge!
Finished reading? Take a quick quiz to see how much you've learned from this tutorial.